#2273 closed enhancement (fixed)
One Step Towards Fine Grained Locking
| Reported by: | Sebastian Huber | Owned by: | Sebastian Huber |
|---|---|---|---|
| Priority: | normal | Milestone: | 4.11 |
| Component: | score | Version: | 4.11 |
| Severity: | normal | Keywords: | |
| Cc: | Blocked By: | ||
| Blocking: |
Description (last modified by Sebastian Huber)
Benefit
Improved average-case performance. Uni-processor configurations will also benefit from some changes since calls to the thread dispatch function are reduced.
Problem Description
The Giant lock is a major performance bottleneck. SMP aware applications tend to use fine grained locking at the application level. So it is important that the semaphore obtain/release sequence for the uncontested case is as fast as possible, as an example see also performance tests with new network stack.
Problem Solution
Remove the Giant lock. This is a very complex task. As a first step a redesign of the semaphore obtain/release sequence should be done. The semaphore objects should use an object specific SMP lock for the non-blocking case and only resort to the Giant lock if a thread must block/unblock or in case of priority inheritance.
The analysis of the current locking protocol shows that it is not compatible with fine grained locking since it uses the executing thread on several places. On SMP systems more than one executing thread exists in contrast to uni-processor systems. The semaphore manager provides the following semaphore object flavours in RTEMS
- counting semaphores (no owner),
- simple binary semaphores (no owner, no protocols),
- binary semaphores,
- binary semaphores with priority ceiling protocol,
- binary semaphores with priority inheritance protocol, and
- binary semaphores with multiprocessor resource sharing protocol (MrsP).
For fine grained locking each flavour must be looked at individually.
Example: Binary Semaphore with Priority Inheritance Protocol
A binary semaphore with priority inheritance protocol has at most one owner at a time. In case an owner is present, then other threads (the rivals) must block and wait for ownership. The highest priority rival will be the new owner once the current owner releases the semaphore. Rivals may use a watchdog to limit the time waiting for ownership. The owner will inherit the priority of the highest priority rival. In the next two images, coloured boxes represent the critical section of the corresponding protection mechanism.
The following image depicts the structure of a binary semaphore of the current implementation with a Giant lock only. The complete operation is protected by the Giant lock with thread dispatching disabled. The interrupts are enabled in general. Some critical sections use disabled interrupts. So interrupts on a processor owning the Giant lock will delay other processors waiting for the Giant lock.
Structure of a binary semaphore with priority inheritance protocol and Giant lock only:

The following image depicts the structure of a binary semaphore with a semaphore specific SMP lock. The state of the semaphore object is protected by this lock. Other state changes like a thread priority change or a thread blocking operation is protected by the Giant lock. The watchdog uses a dedicated lock here, see #2271.
Structure of a binary semaphore with priority inheritance protocol and semaphore specific lock:

In case no owner is present, then the semaphore obtain operation uses only the semaphore object specific SMP lock and there is no interference with the rest of the system.
Attachments (10)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (24)
Changed on 02/17/15 at 18:32:18 by Sebastian Huber
Changed on 02/17/15 at 18:32:32 by Sebastian Huber
comment:1 Changed on 02/17/15 at 18:34:15 by Sebastian Huber
| Description: | modified (diff) |
|---|
comment:2 Changed on 02/18/15 at 14:36:24 by Sebastian Huber
| Status: | new → accepted |
|---|
comment:3 Changed on 02/19/15 at 13:53:31 by Sebastian Huber
comment:4 Changed on 03/04/15 at 11:05:31 by Sebastian Huber <sebastian.huber@…>
In [changeset:"e50297e36caf2c989a03825cc8589cd730c03389/rtems"]:
comment:5 Changed on 03/04/15 at 11:11:39 by Sebastian Huber
comment:6 Changed on 03/06/15 at 10:31:23 by Sebastian Huber
[7d6e94b12ab94f13d3e769702d50f91be7d5884b/rtems]
[4c8a0acc3dd536b3a5684ced8df663931081ba09/rtems]
[5b393fa5b52f2fc2f8f7e0688df86f8b80ab3331/rtems]
[43e1573c1f02194a4fa754dfbff51862130742a5/rtems]
[1512761142b4a4ba6c9c8920f763186ae06dd8ab/rtems]
[222dc775838c73708054db6283723027c5deb56c/rtems]
[6157743d67c79d21996ec2cc9742fd8e4e985be7/rtems]
[b8a5abf3fafa9df7cc0354c0ada6192c38e78354/rtems]
Changed on 03/16/15 at 14:36:17 by Sebastian Huber
| Attachment: | Test_with_fgl.png added |
|---|
Test event send/receive with fine grained locking.
Changed on 03/16/15 at 14:36:38 by Sebastian Huber
| Attachment: | test_with_giant_lock.png added |
|---|
Test event send/receive with Giant lock.
comment:7 Changed on 03/16/15 at 14:50:06 by Sebastian Huber
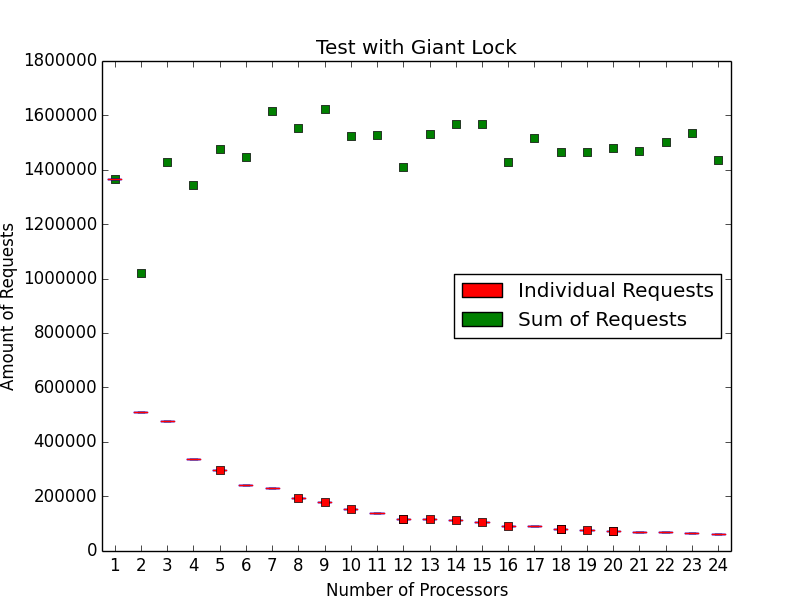
The new test [dc5e5f44485b8f9709da767f79595d2fa8aff74d/rtems] shows that the prototype implementation for the RTEMS events yields a significant improvement for SMP systems in case no blocking operations are involved. The test data is gathered on a 24 processor Freescale T4240 platform with the RTEMS version [6db5e650fb80824c4e9339dfe73976662245d449/rtems].
The first plot shows the count of event send/receive operations for task sets of size 1 to 24 with the patch [7d6e94b12ab94f13d3e769702d50f91be7d5884b/rtems] reverted. The Giant lock limits the total operation count and no benefit from more processors is visible.

The second plot shows the count of event send/receive operations for task sets of size 1 to 24. The sum of the requests per second increases in this test scenario with fine grained locking linearly with the task set cardinality up to the count of processors.

In addition the new implementation (fine grained locking) is more efficient on a task set size of one with 2439242 vs. 1367189 operations per second.
comment:8 Changed on 04/21/15 at 06:26:28 by Sebastian Huber <sebastian.huber@…>
In [changeset:"d3802bb5d708d01d03774b6758ed1e87484b8fac/rtems"]:
comment:9 Changed on 04/21/15 at 06:29:17 by Sebastian Huber
Changed on 05/15/15 at 09:12:27 by Sebastian Huber
| Attachment: | ngmp-events-old.png added |
|---|
Changed on 05/15/15 at 09:12:36 by Sebastian Huber
| Attachment: | ngmp-events-new.png added |
|---|
Changed on 05/15/15 at 09:12:46 by Sebastian Huber
| Attachment: | ngmp-mutex-old.png added |
|---|
Changed on 05/15/15 at 09:12:56 by Sebastian Huber
| Attachment: | ngmp-mutex-new.png added |
|---|
Changed on 05/15/15 at 09:13:25 by Sebastian Huber
| Attachment: | ngmp-msg-old.png added |
|---|
Changed on 05/15/15 at 09:13:33 by Sebastian Huber
| Attachment: | ngmp-msg-new.png added |
|---|
comment:10 Changed on 05/15/15 at 09:47:18 by Sebastian Huber
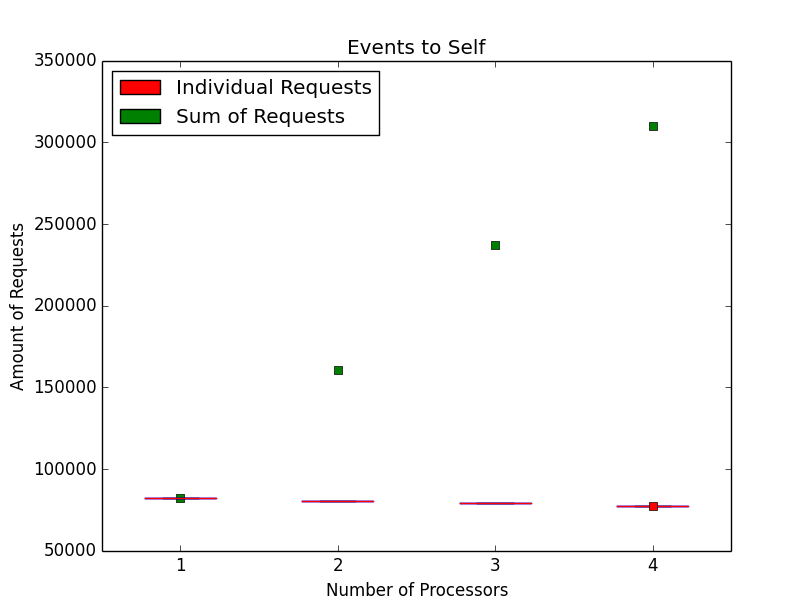
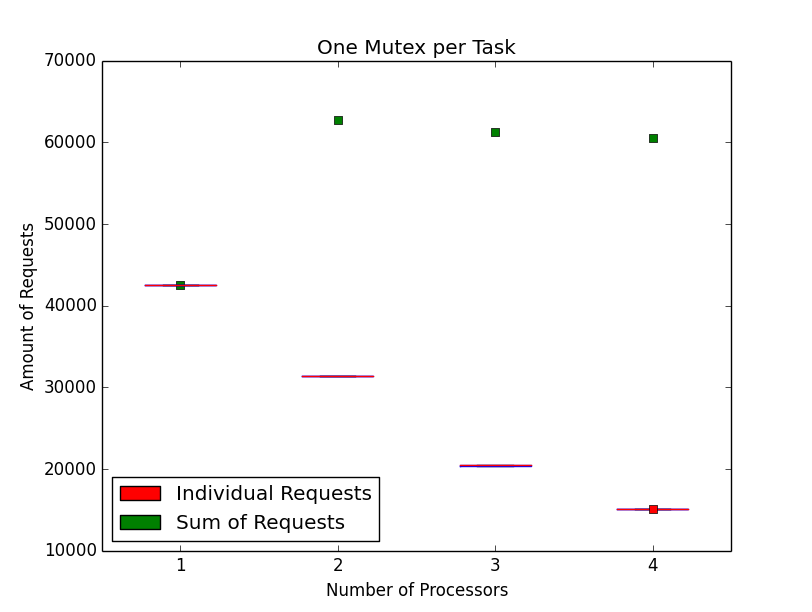
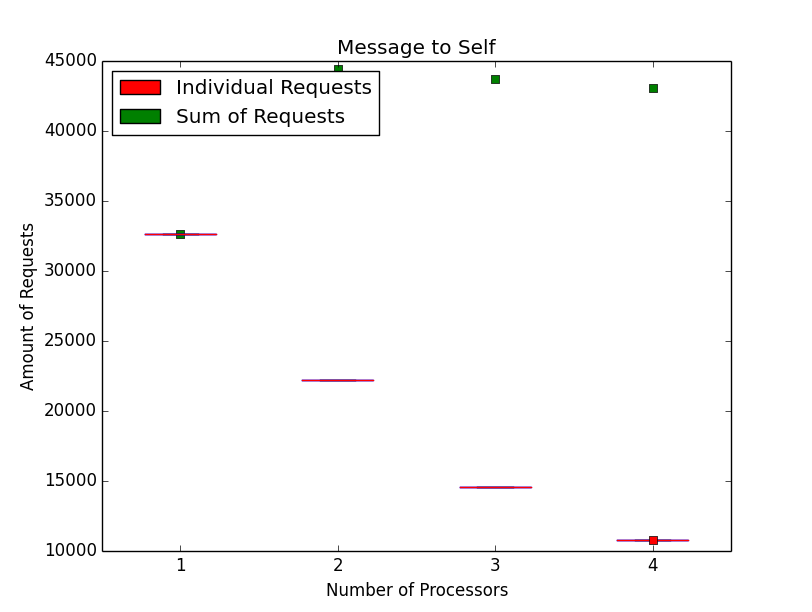
The following test data is gathered on a 4 processor ESA/Gaisler NGMP platform running at 50MHz. Three test cases of the tmtests/tmfine01 test program are presented using RTEMS version [dc5e5f44485b8f9709da767f79595d2fa8aff74d/rtems] with the patch [7d6e94b12ab94f13d3e769702d50f91be7d5884b/rtems] reverted (= old) and a RTEMS version with a fine grained locking implementation for events, semaphores and message queues (= new). The data for the old version is presented before the data for the new version. There is one task per processor.
The first test case sends events to self.


The second test case obtains and releases a mutex private to the task.


The third test case sends and receives a message to self.


The new implementation gets rid of the Giant lock bottleneck and scales well with the processor count. In addition it yields more operations per second on one processor.
| Operations on one Processor (Old) | Operations on one Processor (New) | Change | |
|---|---|---|---|
| Events to Self | 44262 | 82150 | 86% |
| One Mutex per Task | 42520 | 67998 | 60% |
| Message to Self | 32591 | 58596 | 80% |
comment:11 Changed on 05/16/15 at 09:31:43 by Sebastian Huber
| Milestone: | 4.11.1 → 4.11 |
|---|
comment:12 Changed on 05/20/15 at 07:33:16 by Sebastian Huber
| Resolution: | → fixed |
|---|---|
| Status: | accepted → closed |
[b7cff7feb0a0d41ec4876e5ac846bb6cf8254dce/rtems]
[08fe84b5d7072b7809581b1a25954a3b221497a5/rtems]
[02c4c441a51b43b55608893efa4a80a62bb9d4d5/rtems]
[568af83542eec9343c24d417ed6a219d22046233/rtems]
[383cf42217d05a9cf19c6d081d50f92b2262a308/rtems]
[cc366ec8c9ecaab838a745175a0d53a7a5db437e/rtems]
[cc18d7bec7b3c5515cb9e6cd9771d4b94309b3bd/rtems]
[4438ac2575fb9e0760bf53931a52d00dec4deb83/rtems]
[900d337f960cb7cc53f5c93c29a503e5ced2c31f/rtems]
[a816f08478e2fe395062a8114c0654d0624906ae/rtems]
comment:13 Changed on 10/10/17 at 06:27:10 by Sebastian Huber
| Component: | SMP → score |
|---|
comment:14 Changed on 10/10/17 at 06:29:01 by Sebastian Huber
| Component: | score → cpukit |
|---|
[4e3d9a4d6c76fba8e31138d503f736405dafc213/rtems]