| Version 10 (modified by Aanjhan, on 05/20/09 at 03:58:47) (diff) |
|---|
MMU Support
Student : Aanjhan Ranganathan
Mentor : Thomas Doerfler
Abstract
Most modern processors have Memory Management Unit Hardware built into the processor whose main functions are virtual address translation, memory protection and cache control. With RTEMS primarily focused on Embedded Real Time applications, making use of these MMU features especially Memory Protection is important to meet the needs of those applications that requires such support. RTEMS currently does not have MMU support and this project proposes to add this as part of the GSoC Programme.
Current Status and Next Tasks Update
This section of the page contains the current tasks being carried out and if possible any links to finished or ongoing work.
- Collect the information needed for each MMU context
- Creating a suitable set of data structures from that collection
- Creating maybe one or two pictures showing how these data structures are organized
- Creating a sketch of a mid-level API; functions to create/query/remove/modify/switch the MMU context
- Exploring namespace for most of the beow mentioned terminologies
Design Notes
Low Level APIs
Low level APIs will be used to perform operations such as initialisation of MMU registers, PTE generation and storage, exception handling. Except for Exception Handling APIs which shall be triggered from the MMU H/w, the rest will be called by the BSP functions.
Since most of the above actions are architecture specific these APIs shall belong to the libCPU section of RTEMS. Placing it in score/cpu is also an option but since there are varied MMU architectures for the same CPU, it would be better of to place it in libCPU.
Mid Level APIs
The middle layer of the implementation would be architecture independent. This would not just be APIs but is also the layer where the functionality of several actions are going to be present. The complete implementation can fit into the cpukit layer of RTEMS software architecture.
One major functionality of this mid-layer is to manage the 'OS maintained Memory blocks' and assign access attributes. These memory blocks shall be grouped by "contexts". For. E.g each task creates a "MMU Context" which points to a data structure (to be defined) of memory blocks. Each memory block then has attributes associated like "read-only", "don't execute" , "cache-inhibit", "cache-write-through" etc. There shall be APIs to generate/modify/remove these memory blocks which can be used by the higher level applications.
Also there shall be another set of APIs which shall be used by the low level BSP functions to extract information with respect to access rights for a particular block, the access attributes to use etc. This information will then be used by the Low level software to update/create the PTE. Also, a mechanism to inform the low level system of any invalidation/removal/change of status of a memory block is needed. This ensures that the PTE are kept upto date in case of removal of any memory areas.
The Work package Flow
This section shall describe the work package in steps that makes it easy to comprehend and evaluate ones progress. Also this enables us to have fixed goals at various stages of the project.
The various steps can be broadly classified as below
# An API/MMU Port Design Document # Software Architecture decisions (Part of 1 in a way) # Operating Support for Initialisation of MMU - Implementation # Page Table Entry generation (hash tables, exception handling) # Adding a PTE # Removing PTE # POSIX API and
API/MMU Port Design Document
This will be Part 1 and 2 of the package. The document shall describe the various functions planned to support in the Package, Initialisation sequence, Exception handling. Also would contain a brief Software Architecture description (E.g. what shall go into the SuperCore?, what shall go into the libchip etc. A kind of a functional flow diagram)
OS Support for MMU Initialisation =c
The next step in the package would be to get the initialisation of the MMU registers in place. This cannot be tested as such except through reviews since no access to the MMU will be allowed until a PTE is defined.
Page Table Entry Handling
Defining a Page Table entry is implemented here. This would be according to the information available beginning from Section 7.6.2 of the Programmer's Manual for PPC doc [2]. After defining the page entry, the next step is to put this info into the MMu table.
In other words, the next phases would involve implementing
- Adding the PTE
- Removing the PTE from the table.
A deeper look into the generation and storing of the PTEs would lead to one realising that there is not enough space in each PTEG (or hash table) and not all translation info can go into this hardware buffer. Hence there is a necessity to maintain a separate data structure containing info useful for generating the PTE.
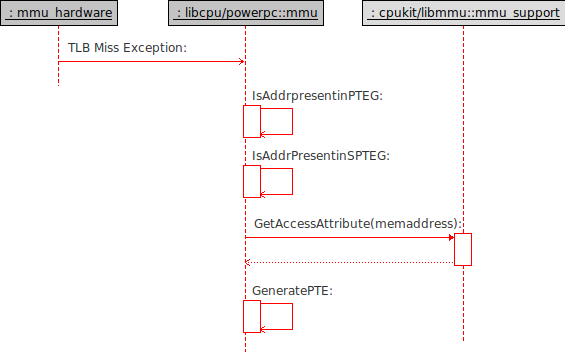
For. e.g. let's say the PPC core tries to access an address that is not stored in the data TLB of the MMU H/W. Then the PPC will issue a "Data TLB miss exception". The data TLB miss exception will use some magic registers to access the PPTEG. The primary page table entry group. The data TLB miss exception will use some magic registers to access the PPTEG. It will search this group for a PTE with a proper pattern. There are about 8 entries in a PPTEG, hence it is possible that the entry is not fond in the primary group and hence the search moves on to the SPTEG. Though the probability of finding the required pattern in SPTEG is more than in the PPTEG, still there is no guarantee. If found, the entry is put into the TLB and function returns. If it fails then the exception rised by the MMU should lead to a look up into a "OS maintained memory table" to create the required PTE and store it in the hash table/insert into the TLB.
This exception handling function needs to be implemented as part of the package too.
POSIX based Memory Protection
Suitability of a POSIX API implementation needs to be explored. All the above implementation are at a lower level in the software design tree and the POSIX APIs work at much higher level. But to come to a concrete decision more study is required. The shmem API is a good starting point.
This makes the work package until now.
Acronyms
{| | PTE | Page Table Entry
| PPTEG | Primary Page Table Entry Group
| SPTEG | Secondary Page Table Entry Group
| VSID | Virtual Segment Identifier
| API | Abbreviated Page Index
| TLB | Translation lookup Buffer
| EA | Effective Address |}
References
Attachments (1)
-
Sequence_diagram.png (15.2 KB) - added by Amar Takhar on 11/23/14 at 05:06:52.
Imported from old wiki.
{kind=link}
{kind=link}
Download all attachments as: .zip