| Version 87 (modified by Chris Johns, on 11/23/14 at 04:55:50) (diff) |
|---|
SMP
Table of Contents
- SMP
- Status of Effort
- Requirements
- Application Impact of SMP
- Design Issues
- Low-Level Start
- Status
- Future Directions
- Processor Affinity
- Status
- Background
- Theory
- Atomic Operations
- Status
- Future Directions
- SMP Locks
- Status
- Future Directions
- ISR Locks
- Status
- Future Directions
- Giant Lock vs. Fine Grained Locking
- Status
- Future Directions
- Watchdog Handler
- Status
- Future Directions
- Per-CPU Control
- Status
- Future Directions
- Interrupt Support
- Status
- Future Directions
- Global Scheduler
- Status
- Future Directions
- Clustered Scheduling
- Status
- Future Directions
- Task Variables
- Status
- Future Directions
- Non-Preempt Mode for Mutual Exclusion
- Status
- Future Directions
- Thread Restart
- Status
- Future Directions
- Thread Delete
- Status
- Future Directions
- Semaphores and Mutexes
- Status
- Future Directions
- Implementations
- Tool Chain
- Binutils
- GCC
- GDB
- Profiling
- Reason
- Status
- RTEMS API Changes
- High-Performance CPU Counters
- SMP Lock Profiling
- Interrupt and Thread Profiling
- Interrupt Support
- Reason
- Status
- RTEMS API Changes
- Clustered Scheduling
- Reason
- Status
- RTEMS API Changes
- Scheduler Configuration
- Scheduler Implementation
- Multiprocessor Resource Sharing Protocol - MrsP
- Reason
- Status
- RTEMS API Changes
- Implementation
- Fine Grained Locking
- Reason
- Status
- RTEMS API Changes
- Locking Protocol Analysis
Status of Effort
The SMP support for RTEMS is a work in progress. Basic support is available for ARM, PowerPC, SPARC and Intel x86.
| Design Issues | Summary | Notes |
| Low Level Start | TBD | |
| Processor Affinity | Ongoing | |
| Atomic Operations | TBD | |
| SMP Locks | TBD | |
| ISR Locks | TBD | |
| Giant Lock vs Fine Grained Locking | TBD | |
| Watchdog Handler | TBD | |
| Per-CPU Control | TBD | |
| Interrupt Support | TBD | |
| Global Scheduler | TBD | |
| Clustered Scheduling | TBD | |
| Task Variables | TBD | |
| Non-Preempt Mode for Mutual Exclusion | TBD | |
| Thread Restart | TBD | |
| Thread Delete | TBD | |
| Semaphores and Mutexes | TBD | |
| Implementation Status | Summary | Notes |
| Tool Chain | TBD | |
| Profiling | Complete | CPU counter support is complete. The profiling support is complete. |
| Interrupt Support | TBD | |
| Clustered Scheduling | Complete | |
| Multiprocessor Resource Sharing Protocol - MrsP | Complete | |
| Fine Grained Locking | TBD | |
| Post-Switch Actions | Complete | Implemented as post-switch thread-actions |
| Thread Delete/Restart | Complete | |
| Barrier Synchronization | Complete | |
| Low-Level Broadcasts | TBD | |
| Termios Framework | Complete |
Requirements
- Implementation Language
- The implementation language shall be C11 (ISO/IEC 9899:2011) or assembler.
- The CPU architecture shall support lock-free atomic operations for unsigned long integers.
- SMP Synchronization Primitives
- Atomic operations and fences shall be used to implement higher-level synchronization primitives.
- An SMP lock which ensures mutual exclusion and FIFO ordering shall be provided.
- An SMP read-write lock shall be provided which offers phase-fair ordering <ref name="BrandenburgAnderson2010">Björn B. Brandenburg and James H. Anderson, Spin-Based Reader-Writer Synchronization for Multiprocessor Real-Time Systems, July 2010.</ref>.
- A re-usable SMP barrier shall be provided.
- SMP synchronization primitives may execute infinitely without progress in case other processors execute erroneous code.
- System Initialization and Shutdown
- Before execution starts on the entry symbol on at least one processor a boot loader must load the text and read-only sections.
- A read-only application configuration shall select the boot processor.
- The boot processor shall initialize the data and BSS sections if not already performed by a boot loader.
- A CPU architecture or BSP specific method shall ensure that objects resident in the data or BSS section are not accessed before the boot processor or boot loader initialized these sections.
- The boot processor shall execute the serial system initialization.
- It shall be possible to shutdown the system anytime after data and BSS section initialization from any processor.
- The fatal extension handler shall be invoked during system shutdown on each processor.
- Invocation of the shutdown procedure while holding SMP synchronization primitives may lead to dead-lock.
- Thread Life Cycle
- Asynchronous thread deletion shall be possible.
- Concurrent thread deletion shall be possible. At most one thread shall start the deletion process successfully, other threads shall observe an error status.
- Usage of thread identifiers which are re-used by newly created threads with the aim to access a deleted thread may lead to unpredictable results.
- Threads shall have a method to change and restore the ability for asynchronous thread deletion of the executing thread.
- The POSIX cleanup handler shall be available for all RTEMS build configurations.
- The POSIX cleanup handler shall execute in the context of the deleted thread.
- The POSIX cleanup handler shall execute in case a thread is re-started in the context of the re-started thread.
- The POSIX keys shall be available for all RTEMS build configurations.
- The POSIX key destructor shall execute in the context of the deleted thread.
- The POSIX key destructor shall execute in case a thread is re-started in the context of the re-started thread.
- In case a thread owns semaphore objects after the cleanup procedure, then this shall result in a fatal error.
- Non-Thread Object Life Cycle
- Concurrent object deletion is for example deletion requests issued by multiple threads for one object or usage of an object while a deletion request was issued.
- Concurrent object deletion may have unpredictable results.
- Usage of objects during deletion of this object may have unpredictable results.
- Classic API
- Usage of task variables shall lead to a compile time error.
- Usage of task non-preempt mode shall lead to a compile time error.
- Usage of interrupt disable/enable shall lead to a run-time time error if RTEMS debug is enabled and the executing context is unsafe.
- All other RTEMS object services shall behave like in the single-processor configuration.
- Profiling
- The profiling shall be a RTEMS build configuration option.
- It shall be possible to measure time intervals up to the system tick interval with little overhead in every execution context.
- It shall be possible to obtain profiling information for the lowest-level system operations like thread dispatch disabled sections, interrupt processing and SMP locks.
- There shall be a method for the application to retrieve profiling information of the system.
- Interrupt Support
- Interrupts shall have an interrupt affinity to the boot processor by default.
- It shall be possible to set the interrupt affinity of interrupt sources.
- Clustered/Partitioned? Scheduling
- RTEMS shall allow the set of processors in a system to be partitioned into pairwise disjoint subsets. Each subset of processors shall be owned by exactly one scheduler instance.
- A clustered/partitioned fixed-priority scheduler shall be provided.
- The application configuration shall provide a set of processors which may be used to run the application.
- The application configuration shall define the scheduler instances.
- The CPU architecture or BSP shall be able to reduce the set of processors provided by the application configuration to reflect the actual hardware.
- The application configuration of a scheduler instance shall specify if the set of processors can be reduced.
- The application configuration of a scheduler instance shall specify if the set of processors can be expanded with processors available by the actual hardware and not assigned to other scheduler instances.
- Fine Grained Locking
- No giant lock protecting the system state shall be necessary.
- Non-blocking operations shall use only an object specific lock.
Application Impact of SMP
TBD
- Task Variables
- Interrupt Disable/Enable?
- No Preempt
- Keys
- Thread Local Storage
Design Issues
Low-Level Start
Status
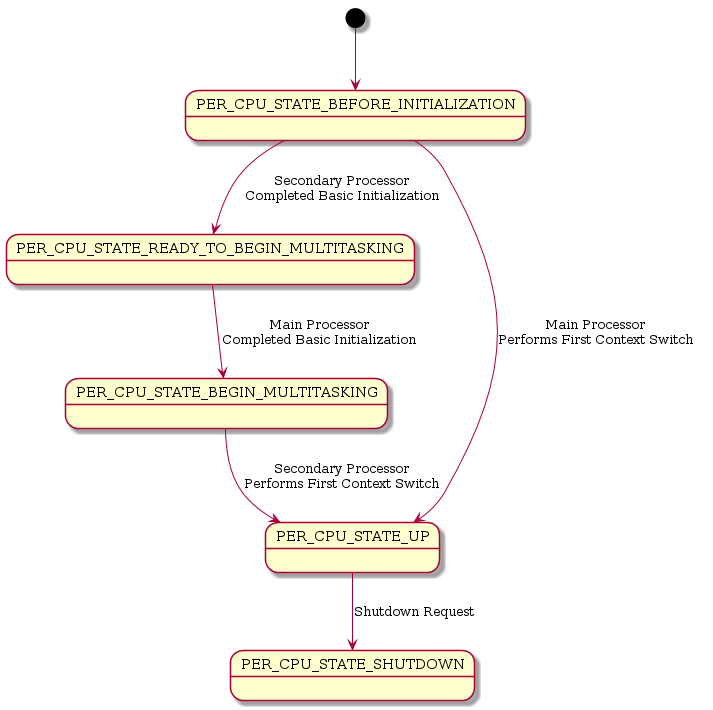
The low-level start is guided by the per-CPU control state Per_CPU_Control::state. See also _Per_CPU_Change_state() and _Per_CPU_Wait_for_state().
File:rtems-smp-low-level-states.png?
Future Directions
None.
Processor Affinity
Status
As of 15 April 2014, a scheduler with support for managing the data associated with thread processor affinity has been added. The actual affinity logic in the scheduler remains to be implemented.
The APIs for <sys/cpuset.h>, pthread affinity, and Classic API task affinity have been community reviewed and patches have been posted. The current work is "data complete" in that one can get and set using the APIs but no scheduler currently supports affinity.
Background
There are multiple pieces of work involved in supporting thread processor affinity
- the POSIX application level API,
- the Classic application level API,
- scheduler framework modifications, and
- actual scheduler support.
There is no POSIX API available that covers thread processor affinity. Linux is the de facto standard system for high performance computing so it is obvious to choose a Linux compatible API for RTEMS. Linux provides CPU_SET(3) to manage sets of processors. Thread processor affinity can be controlled via SCHED_SETAFFINITY(2) and PTHREAD_SETAFFINITY_NP(3).
- Once the work is complete, RTEMS will provide these APIs. The implementation shares no code with GNU/Linux since it is not possible to use the Linux files directly since they have a pure GPL license.
Work remains to be done on adding affinity to a new SMP Scheduler variant. The current plan calls for having the schedulers without affinity ignore input on a set affinity operation and return a cpu set with all CPUs set on all get affinity operations. A new SMP scheduler variant will be added to support affinity. Initially, this scheduler will only be sufficient to properly manage the thread's CPU set as a data element. Then an assignment algorithm will be added.
Theory
The scheduler support for arbitrary processor affinities is a major challenge. Schedulability analysis for schedulers with arbitrary processor affinities is a current research topic <ref name="Gujarati2013>Arpan Gujarati, Felipe Cerqueira, and Björn Brandenburg. Schedulability Analysis of the Linux Push and Pull Scheduler with Arbitrary Processor Affinities, Proceedings of the 25th Euromicro Conference on Real-Time Systems (ECRTS 2013), July 2013.</ref>.
Support for arbitrary processor affinities may lead to massive thread migrations in case a new thread is scheduled. Suppose we have M processors 0, ..., M - 1 and M + 1 threads 0, ..., M. Thread i can run on processors i and i + 1 for i = 0, ..., M - 2. The thread M - 1 runs only on processor M - 1. The M runs only on processor 0. A thread i has a higher priority than thread i + 1 for i = 0, ..., M, e.g. thread 0 is the highest priority thread. Suppose at time T0 threads 0, ..., M - 2 and M are currently scheduled. The thread i runs on processor i + 1 for i = 0, ..., M - 2 and thread M runs on processor 0. Now at time T1 thread M - 1 gets ready. It casts out thread M since this is the lowest priority thread. Since thread M - 1 can run only on processor M - 1, the threads 0, ..., M - 2 have to migrate from processor i to processor i - 1 for i = 0, ..., M - 2. So one thread gets ready and the threads of all but one processor must migrate. The threads forced to migrate all have a higher priority than the new ready thread M - 1. {| class="wikitable" |+ align="bottom" | Example for M = 3 ! Time ! Thread ! Processor 0 ! Processor 1 ! Processor 2
| rowspan="4" | T0 | 0 | | style="background-color:green" | |
| 1 | | | style="background-color:yellow" |
| 2 | | |
| 3 | style="background-color:red" | | |
| rowspan="4" | T1 | 0 | style="background-color:green" | | |
| 1 | | style="background-color:yellow" | |
| 2 | | | style="background-color:purple" |
| 3 | | |
|}
In the example above the Linux Push and Pull scheduler would not find a processor for thread M - 1 = 2 and thread M = 3 would continue to execute even though it has a lower priority.
The general scheduling problem with arbitrary processor affinities is a matching problem in a bipartite graph. There are two disjoint vertex sets. The set of ready threads and the set of processors. The edges indicate that a thread can run on a processor. The scheduler must find a maximum matching which fulfills in addition other constraints. For example the highest priority threads should be scheduled first. The performed thread migrations should be minimal. The augmenting path algorithm needs O(VE) time to find a maximum matching, here V is the ready thread count plus processor count and E is the number of edges. It is particularly bad that the time complexity depends on the ready thread count. It is an open problem if an algorithm exits that is good enough for real-time applications.
Atomic Operations
Status
The <stdatomic.h> header file is now available in Newlib. GCC 4.8 supports C11 atomic operations. Proper atomic operations support for LEON3 is included in GCC 4.9. According to the SPARC GCC maintainer it is possible to back port this to GCC 4.8. A GSoC 2013 project works on an atomic operations API for RTEMS. One part will be a read-write lock using a phase-fair lock implementation.
Example ticket lock with C11 atomics.
#include <stdatomic.h>
struct ticket {
atomic_uint ticket; atomic_uint now_serving;
};
void acquire(struct ticket *t) {
unsigned int my_ticket = atomic_fetch_add_explicit(&t->ticket, 1, memory_order_relaxed);
while (atomic_load_explicit(&t->now_serving, memory_order_acquire) != my_ticket) {
/* Wait */
}
}
void release(struct ticket *t) {
unsigned int current_ticket = atomic_load_explicit(&t->now_serving, memory_order_relaxed);
atomic_store_explicit(&t->now_serving, current_ticket + 1U, memory_order_release);
}
The generated assembler code looks pretty good. Please note that GCC generates CAS instructions and not CASA instructions.
.file "ticket.c" .section ".text" .align 4 .global acquire .type acquire, #function .proc 020
acquire:
ld [%o0], %g1 mov %g1, %g2
.LL7:
add %g1, 1, %g1 cas [%o0], %g2, %g1 cmp %g1, %g2 bne,a .LL7
mov %g1, %g2
add %o0, 4, %o0
.LL4:
ld [%o0], %g1 cmp %g1, %g2 bne .LL4
nop
jmp %o7+8
nop
.size acquire, .-acquire .align 4 .global release .type release, #function .proc 020
release:
ld [%o0+4], %g1 add %g1, 1, %g1 st %g1, [%o0+4] jmp %o7+8
nop
.size release, .-release .ident "GCC: (GNU) 4.9.0 20130917 (experimental)"
Future Directions
- Review and integrate the GSoC work.
- Make use of atomic operations.
SMP Locks
Status
SMP locks are implemented as a ticket lock using CPU architecture specific atomic operations. The SMP locks use a local context to be able to use scalable lock implementations like the Mellor-Crummey and Scotty (MCS) queue-based locks.
Future Directions
Introduce read-write locks. Use phase-fair read-write lock implementation. This can be used for example by the time management code. The system time may be read frequently, but updates are infrequent.
ISR Locks
Status
On single processor configurations disabling of interrupts ensures mutual exclusion. This is no longer true on SMP since other processors continue to execute freely. On SMP the disabling of interrupts must be combined with an SMP lock. The ISR locks degrade to simple interrupt disable/enable sequences on single processor configurations. On SMP configurations they use an SMP lock to ensure mutual exclusion throughout the system.
Future Directions
- See SMP locks.
- Ensure via a RTEMS assertion that normal interrupt disable/sequences are only used intentional outside of the Giant lock critical sections. Review usage of ISR disable/enable sequences of the complete code base.
Giant Lock vs. Fine Grained Locking
Status
The operating system state is currently protected by three things
- the per-processor thread dispatch disable level,
- the Giant lock (a global recursive SMP lock), and
- the disabling of interrupts.
For example the operating services like rtems_semaphore_release() follow this pattern:
operation(id):
disable_thread_dispatching() acquire_giant_lock() obj = get_obj_by_id(id) status = obj->operation() put_object(obj) release_giant_lock() enable_thread_dispatching() return status
All high level operations are serialized due to the Giant lock. The introduction of the Giant lock allowed a straight forward usage of the existing single processor code in an SMP configuration. However a Giant lock will likely lead to undesirable high worst case latencies which linear increase with the processor count <ref name="Brandenburg2011">Björn B. Brandenburg, Scheduling and Locking in Multiprocessor Real-Time Operating Systems, 2011.</ref>.
Future Directions
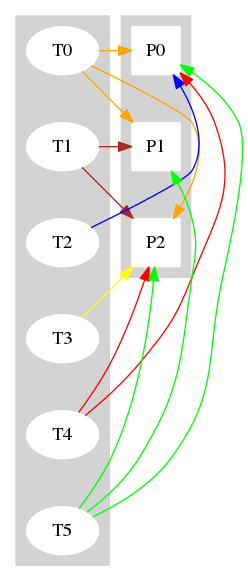
The Giant lock should be replaced with fine grained locking. In order to introduce fine grained locking the state transitions inside a section protected by the Giant lock must be examined. As an example the event send and receive operations are presented in a simplified state diagram.
The colour indicates which locks are held during a state and state transition. In case of a blocking operation we have four synchronization states which are used to split up the complex blocking operation into parts in order to decrease the interrupt latency
- nothing happened,
- satisfied,
- timeout, and
- synchronized.
This state must be available for each thread and resource (e.g. event, semaphore, message queue). Since this would lead to a prohibitive high memory demand and a complicated implementation some optimizations have been performed in RTEMS. For events a global variable is used to indicate the synchronization state. For resource objects the synchronization state is part of the object. Since at most one processor can execute a blocking operation (ensured by the Giant lock or the singe processor configuration) it is possible to use the state variable only for the executing thread.
In case one SMP lock is used per resource the resource must indicate which thread is about to perform a blocking operation since more than one executing thread exists. For example two threads can try to obtain different semaphores on different processors at the same time.
A blocking operation will use not only the resource object, but also other resources like the scheduler shared by all threads of a dispatching domain. Thus the scheduler needs its own locks. This will lead to nested locking and deadlocks must be prevented.
Watchdog Handler
Status
The Watchdog Handler is a global resource which provides time management in RTEMS. It is a core service of the operating system and used by the high level APIs. It is used for time of day maintenance and time events based on ticks or wall clock time for example. The term watchdog has nothing to do with hardware watchdogs.
Future Directions
The watchdog uses delta chains to manage time based events. One global watchdog resource leads to scalability problems. A SMP system is scalable if additional processors will increase the performance metrics. If we add more processors, then in general the number of timers increases proportionally and thus leads to longer delta chains. Also the chance for lock contention increases. Thus the watchdog resource should move to the scheduler scope with per scheduler instances. Additional processors can then use new scheduler instances.
Per-CPU Control
Status
Per-CPU control state is available for each configured CPU in a statically created global table _Per_CPU_Information. Each per-CPU control is cache aligned to prevent false sharing and to provide simple access via assembly code. CPU ports can add custom fields to the per-CPU control. This is used on SPARC for the ISR dispatch disable indication.
Future Directions
None.
Interrupt Support
Status
The interrupt support is BSP specific in general.
Future Directions
- The SMP capable BSPs should implement the Interrupt Manager Extension.
- Add interrupt processor affinity API to Interrupt Manager Extension. This should use the affinity sets API used for thread processor affinity.
Global Scheduler
Status
- Scheduler selection is a link-time configuration option.
- Basic SMP support for schedulers like processor allocation and extended thread state information.
- Two global fixed priority schedulers (G-FP) are available with SMP support.
Future Directions
- Add more schedulers, e.g. EDF, phase-fair, early-release fair, etc.
- Allow thread processor affinity selection for each thread.
- The scheduler operations have no context parameter instead they use the global variable '_Scheduler'. The scheduler operations signature should be changed to use a parameter for the scheduler specific context to allow more than one scheduler in the system. This can be used to enable scheduler hierarchies or partitioned schedulers.
- The scheduler locking is inconsistent. Some scheduler operations are invoked with interrupts disabled. Some like the yield operations are called without interrupts disabled and must disable interrupts locally.
- The new SMP schedulers lack test coverage.
- Implement clustered (or partitioned) scheduling with a sophisticated resource sharing protocol (e.g. <ref name="BurnsWellings2013">A. Burns and A.J. Wellings, A Schedulability Compatible Multiprocessor Resource Sharing Protocol - MrsP, Proceedings of the 25th Euromicro Conference on Real-Time Systems (ECRTS 2013), July 2013. </ref>). To benefit from this the Giant lock must be eliminated.
Clustered Scheduling
Status
Clustered scheduling is not supported.
Future Directions
Suppose we have a set of processors. The set of processors can be partitioned into non-empty, pairwise disjoint subsets. Such a subset is called a dispatching domain. Dispatching domains should be set up in the initialization phase of the system before application-level threads (and worker threads) can be attached to them. For now the partition must be specified by the application at linktime: this restriction is acceptable in this study project as no change should be allowable to dispatching domains at run time. Associated with each dispatching domain is exactly one scheduler instance. This association (which defines the scheduler algorithm for the domain) must be specified by the application at linktime, upon or after the creation of the dispatching domain. So we have clustered scheduling.
At any one time a thread belongs to exactly one dispatching domain. There will be no scheduling hierarchies and no intersections between dispatching domains. If no dispatching domain is explicitly specified, then it will inherit the one from the executing context to support external code that is not aware of clustered scheduling. This inheritance feature is erroneous and static checks should be made on the program code and link directives to prevent it from happening in this study project.
Do we need the ability to move a thread from one dispatching domain to another? Application-level threads do not migrate. Worker threads do no either. Worker threads do no either. The only allowable (and desirable) migration is for the execution of application-level threads in global resources - not the full task, only that protected execution - in accord with <ref name="BurnsWellings2013"/>.
Task Variables
Status
Task variables cannot be used on SMP. The alternatives are thread-local storage, POSIX keys or special access functions using the thread control block of the executing thread. For Newlib the access to the re-entrancy structure is now performed via getreent(), see also DYNAMIC_REENT in Newlib. The POSIX keys and the POSIX once function are now available for all RTEMS configurations (they no longer depend on POSIX enabled). Task variables have been replaced with POSIX keys for the RTEMS shell, the file system environment and the C++ support.
Future Directions
- Fix Ada self task reference.
Non-Preempt Mode for Mutual Exclusion
Status
Disabling of thread preemption cannot be used to ensure mutual exclusion on SMP. The non-preempt mode is disabled on SMP and a run-time error will occur if such a mode change request is issued. The alternatives are mutexes and condition variables.
Future Directions
- Add condition variables to the Classic API.
- Fix pthread_once().
- Fix the block device cache bdbuf.
- Fix C++ support.
Thread Restart
Status
The restart of threads is implemented.
Future Directions
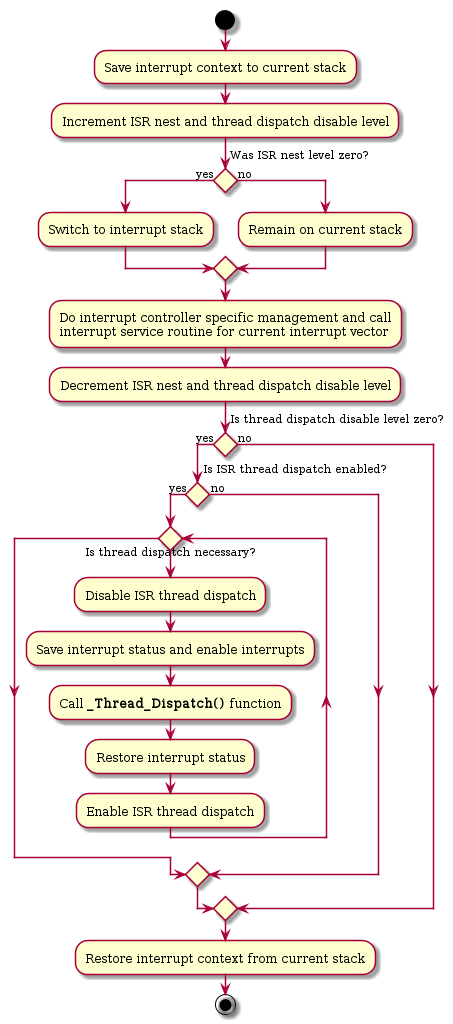
The restart of threads is implemented via post-switch thread actions. The post-switch thread actions use the per-CPU lock and have very little overhead if no post-switch actions must be performed. Most architectures should be updated to use an interrupt epilogue similar to the SPARC to avoid long interrupt disable times.
Why execute post-switch handlers with interrupts disabled on some architectures (e.g. ARM and PowerPC)? The most common interrupt handling sequence looks like this:
In this sequence it is not possible to enable interrupts around the _Thread_Dispatch() call. This could lead to an unlimited number of interrupt contexts saved on the thread stack. To overcome this issue some architectures use a flag variable that indicates this particular execution environment (e.g. the SPARC). Here the sequence looks like this:
The ISR thread dispatch disable flag must be part of the thread context. The context switch will save/restore the per-CPU ISR dispatch disable flag to/from the thread context. Each thread stack must have space for at least two interrupt contexts.
This scheme could be used for all architectures.
Thread Delete
Status
Deletion of threads is implemented.
Future Directions
None.
Semaphores and Mutexes
Status
The semaphore and mutex objects use _Objects_Get_isr_disable(). On SMP configurations this first acquires the Giant lock and then interrupts are disabled.
Future Directions
Use an ISR lock per object to improve the performance for uncontested operations. See also Giant Lock vs. Fine Grained Locking.
Implementations
Tool Chain
Binutils
A Binutils 2.24 or later release must be used due to the LEON3 support.
GCC
A GCC 4.8 2013-11-25 (e.g. 4.8.3) or later must be used due to the LEON3 support. The LEON3 support for GCC includes a proper C11 memory model definition for this processor and C11 atomic operations using the CAS instruction. The backport of the LEON3 support was initiated by EB http://gcc.gnu.org/ml/gcc-patches/2013-11/msg02255.html.
GDB
Current GDB versions have problems with the debug format generated by GCC 4.8 and later https://sourceware.org/bugzilla/show_bug.cgi?id=16215.
Profiling
Reason
SMP lock and interrupt processing profiling is necessary to fulfill some observability requirements. Vital timing data can be gathered on a per object basis through profiling.
Status
CPU counter support is complete http://git.rtems.org/rtems/commit/?id=24bf11eca11947d961cc9bb5f7d92dabff169e93. The profiling support is complete http://git.rtems.org/rtems/commit/?id=4dad4b84112d57cf6e77409f8e267706db446ec0.
RTEMS API Changes
None.
High-Performance CPU Counters
In order to measure short time intervals we have to add a high-performance CPU counter support to the CPU port API. This is can be also used as an replacement for the BSP specific benchmark timers. It may also be used to implement busy wait loops which are required by some device drivers.
/
- @brief Integer type for CPU counter values. */
typedef XXX CPU_counter;
/
- brief Returns the current CPU counter value. */
CPU_counter _CPU_counter_Get()
/
- brief Mask for arithmetic operations with the CPU counter value. *
- All arithmetic operations are defined as A = ( C op B ) & MASK. */
CPU_counter _CPU_counter_Mask()
/
- brief Converts a CPU counter value into nanoseconds. */
uint64_t _CPU_counter_To_nanoseconds( CPU_counter counter )
SMP Lock Profiling
The SMP lock profiling will be a RTEMS build configuration time option (RTEMS_LOCK_PROFILING). The following statistics are proposed.
#define SMP_LOCK_STATS_CONTENTION_COUNTS 4
/
- @brief SMP lock statistics. *
- The lock acquire attempt instant is the point in time right after the
- interrupt disable action in the lock acquire sequence. *
- The lock acquire instant is the point in time right after the lock
- acquisition. This is the begin of the critical section code execution. *
- The lock release instant is the point in time right before the interrupt
- enable action in the lock release sequence. *
- The lock section time is the time elapsed between the lock acquire instant
- and the lock release instant. *
- The lock acquire time is the time elapsed between the lock acquire attempt
- instant and the lock acquire instant. */
struct SMP_lock_Stats { #ifdef RTEMS_LOCK_PROFILING
/
- @brief The last lock acquire instant in CPU counter ticks. *
- This value is used to measure the lock section time. */
CPU_counter acquire_instant;
/
- @brief The maximum lock section time in CPU counter ticks. */
CPU_counter max_section_time;
/
- @brief The maximum lock acquire time in CPU counter ticks. */
CPU_counter max_acquire_time;
/
- @brief The count of lock uses. *
- This value may overflow. */
uint64_t usage_count;
/
- @brief The counts of lock acquire operations with contention. *
- The contention count for index N corresponds to a lock acquire attempt
- with an initial queue length of N + 1. The last index corresponds to all
- lock acquire attempts with an initial queue length greater than or equal
- to SMP_LOCK_STATS_CONTENTION_COUNTS. *
- The values may overflow. */
uint64_t contention_counts[SMP_LOCK_STATS_CONTENTION_COUNTS];
/
- @brief Total lock section time in CPU counter ticks. *
- The average lock section time is the total section time divided by the
- lock usage count. *
- This value may overflow. */
uint64_t total_section_time;
#endif /* RTEMS_LOCK_PROFILING */ }
struct SMP_lock_Control {
... lock data ... SMP_lock_Stats Stats;
};
A function should be added to monitor the lock contention.
/
- @brief Called in case of lock contention. *
- @param[in] counter The spin loop iteration counter. */
void _SMP_lock_Contention_monitor(
const SMP_lock_Control *lock, int counter
);
A ticket lock can then look like this:
void acquire(struct ticket *t) {
unsigned int my_ticket = atomic_fetch_add_explicit(&t->ticket, 1, memory_order_relaxed);
#ifdef RTEMS_LOCK_PROFILING
int counter = 0;
#endif /* RTEMS_LOCK_PROFILING */
while (atomic_load_explicit(&t->now_serving, memory_order_acquire) != my_ticket) {
#ifdef RTEMS_LOCK_PROFILING
++counter; _SMP_lock_Contention_monitor(t, counter);
#endif /* RTEMS_LOCK_PROFILING */
}
}
SMP lock statistics can be evaluated use the following method.
typedef void ( *SMP_lock_Visitor )(
void *arg, SMP_lock_Control *lock, SMP_lock_Class lock_class, Objects_Name lock_name
);
/
- @brief Iterates through all system SMP locks and invokes the visitor for
- each lock. */
void _SMP_lock_Iterate( SMP_lock_Visitor visitor, void *arg );
Interrupt and Thread Profiling
The interrupt and thread profiling will be a RTEMS build configuration time option (RTEMS_INTERRUPT_AND_THREAD_PROFILING).
The time spent on interrupts and the time of disabled thread dispatching should be monitored per-processor. The time between the interrupt recognition by the processor and the actuals start of the interrupt handler code execution should be monitored per-processor if the hardware supports this.
/
- @brief Per-CPU statistics. */
struct Per_CPU_Stats { #ifdef RTEMS_INTERRUPT_AND_THREAD_PROFILING
/
- @brief The thread dispatch disabled begin instant in CPU counter ticks. *
- This value is used to measure the time of disabled thread dispatching. */
CPU_counter thread_dispatch_disabled_instant;
/
- @brief The last outer-most interrupt begin instant in CPU counter ticks. *
- This value is used to measure the interrupt processing time. */
CPU_counter outer_most_interrupt_instant;
/
- @brief The maximum interrupt delay in CPU counter ticks if supported by
- the hardware. */
CPU_counter max_interrupt_delay;
/
- @brief The maximum time of disabled thread dispatching in CPU counter
- ticks. */
CPU_counter max_thread_dispatch_disabled_time;
/
- @brief Count of times when the thread dispatch disable level changes from
- zero to one in thread context. *
- This value may overflow. */
uint64_t thread_dispatch_disabled_count;
/
- @brief Total time of disabled thread dispatching in CPU counter ticks. *
- The average time of disabled thread dispatching is the total time of
- disabled thread dispatching divided by the thread dispatch disabled
- count. *
- This value may overflow. */
uint64_t total_thread_dispatch_disabled_time;
/
- @brief Count of times when the interrupt nest level changes from zero to
- one. *
- This value may overflow. */
uint64_t interrupt_count;
/
- @brief Total time of interrupt processing in CPU counter ticks. *
- The average time of interrupt processing is the total time of interrupt
- processing divided by the interrupt count. *
- This value may overflow. */
uint64_t total_interrupt_time;
#endif /* RTEMS_INTERRUPT_AND_THREAD_PROFILING */ }
struct Per_CPU_Control {
... per-CPU data ... Per_CPU_Stats Stats;
};
Interrupt Support
Reason
Applications should be able to distribute the interrupt load throughout the system. In combination with partitioned/clustered scheduling this can reduce the amount of inter-processor synchronization and thread migrations.
Status
This is TBD.
RTEMS API Changes
Each interrupt needs a processor affinity set in the RTEMS SMP configuration. The rtems_interrupt_handler_install() function will not alter the processor affinity set of the interrupt vector. At system start-up all interrupts except the inter-processor interrupts must be initialized to have a affinity with the initialization processor only.
Two new functions should be added to alter and retrieve the processor affinity sets of interrupt vectors.
/
- @brief Sets the processor affinity set of an interrupt vector. *
- @param[in] vector The interrupt vector number.
- @param[in] affinity_set_size Size of the specified affinity set buffer in
- bytes. This value must be positive.
- @param[in] affinity_set The new processor affinity set for the interrupt
- vector. This pointer must not be @c NULL. A set bit in the affinity set
- means that the interrupt can occur on this processor and a cleared bit
- means the opposite. *
- @retval RTEMS_SUCCESSFUL Successful operation.
- @retval RTEMS_INVALID_ID The vector number is invalid.
- @retval RTEMS_INVALID_CPU_SET Invalid processor affinity set. */
rtems_status_code rtems_interrupt_set_affinity(
rtems_vector vector, size_t affinity_set_size, const cpu_set_t *affinity_set
);
/
- @brief Gets the processor affinity set of an interrupt vector. *
- @param[in] vector The interrupt vector number.
- @param[in] affinity_set_size Size of the specified affinity set buffer in
- bytes. This value must be positive.
- @param[out] affinity_set The current processor affinity set of the
- interrupt vector. This pointer must not be @c NULL. A set bit in the
- affinity set means that the interrupt can occur on this processor and a
- cleared bit means the opposite. *
- @retval RTEMS_SUCCESSFUL Successful operation.
- @retval RTEMS_INVALID_ID The vector number is invalid.
- @retval RTEMS_INVALID_CPU_SET The affinity set buffer is too small for the
- current processor affinity set of the interrupt vector. */
rtems_status_code rtems_interrupt_get_affinity(
rtems_vector vector, size_t affinity_set_size, cpu_set_t *affinity_set
);
Clustered Scheduling
Reason
Partitioned/clustered scheduling helps to control the worst-case latencies in the system. The goal is to reduce the amount of shared state in the system and thus prevention of lock contention. Modern multi-processor systems tend to have several layers of data and instruction caches. With partitioned/clustered scheduling it is possible to honor the cache topology of a system and thus avoid expensive cache synchronization traffic.
Status
Support for clustered/partitioned scheduling is complete http://git.rtems.org/rtems/commit/?id=c5831a3f9af11228dbdaabaf01f69d37e55684ef.
RTEMS API Changes
Functions for scheduler management.
/
- @brief Identifies a scheduler by its name. *
- The scheduler name is determined by the scheduler configuration. *
- @param[in] name The scheduler name.
- @param[out] scheduler_id The scheduler identifier associated with the name. *
- @retval RTEMS_SUCCESSFUL Successful operation.
- @retval RTEMS_INVALID_NAME Invalid scheduler name. */
rtems_status_code rtems_scheduler_ident(
rtems_name name, rtems_id *scheduler_id
);
/
- @brief Gets the set of processors owned by the scheduler. *
- @param[in] scheduler_id Identifier of the scheduler.
- @param[in] processor_set_size Size of the specified processor set buffer in
- bytes. This value must be positive.
- @param[out] processor_set The processor set owned by the scheduler. This
- pointer must not be @c NULL. A set bit in the processor set means that
- this processor is owned by the scheduler and a cleared bit means the
- opposite. *
- @retval RTEMS_SUCCESSFUL Successful operation.
- @retval RTEMS_INVALID_ID Invalid scheduler identifier.
- @retval RTEMS_INVALID_CPU_SET The processor set buffer is too small for the
- set of processors owned by the scheduler. */
rtems_status_code rtems_scheduler_get_processors(
rtems_id scheduler_id, size_t processor_set_size, cpu_set_t *processor_set
);
Each thread needs a processor affinity set in the RTEMS SMP configuration. The rtems_task_create() function will use the processor affinity set of the executing thread to initialize the processor affinity set of the created task. This enables backward compatibility for existing software.
Two new functions should be added to alter and retrieve the processor affinity sets of tasks.
/
- @brief Sets the processor affinity set of a task. *
- @param[in] task_id Identifier of the task. Use @ref RTEMS_SELF to select
- the executing task.
- @param[in] affinity_set_size Size of the specified affinity set buffer in
- bytes. This value must be positive.
- @param[in] affinity_set The new processor affinity set for the task. This
- pointer must not be @c NULL. A set bit in the affinity set means that the
- task can execute on this processor and a cleared bit means the opposite. *
- @retval RTEMS_SUCCESSFUL Successful operation.
- @retval RTEMS_INVALID_ID Invalid task identifier.
- @retval RTEMS_INVALID_CPU_SET Invalid processor affinity set. */
rtems_status_code rtems_task_set_affinity(
rtems_id task_id, size_t affinity_set_size, const cpu_set_t *affinity_set
);
/
- @brief Gets the processor affinity set of a task. *
- @param[in] task_id Identifier of the task. Use @ref RTEMS_SELF to select
- the executing task.
- @param[in] affinity_set_size Size of the specified affinity set buffer in
- bytes. This value must be positive.
- @param[out] affinity_set The current processor affinity set of the task.
- This pointer must not be @c NULL. A set bit in the affinity set means that
- the task can execute on this processor and a cleared bit means the
- opposite. *
- @retval RTEMS_SUCCESSFUL Successful operation.
- @retval RTEMS_INVALID_ID Invalid task identifier.
- @retval RTEMS_INVALID_CPU_SET The affinity set buffer is too small for the
- current processor affinity set of the task. */
rtems_status_code rtems_task_get_affinity(
rtems_id task_id, size_t affinity_set_size, cpu_set_t *affinity_set
);
Two new functions should be added to alter and retrieve the scheduler of tasks.
/
- @brief Sets the scheduler of a task. *
- @param[in] task_id Identifier of the task. Use @ref RTEMS_SELF to select
- the executing task.
- @param[in] scheduler_id Identifier of the scheduler. *
- @retval RTEMS_SUCCESSFUL Successful operation.
- @retval RTEMS_INVALID_ID Invalid task identifier.
- @retval RTEMS_INVALID_SECOND_ID Invalid scheduler identifier. *
- @see rtems_scheduler_ident(). */
rtems_status_code rtems_task_set_scheduler(
rtems_id task_id, rtems_id scheduler_id
);
/
- @brief Gets the scheduler of a task. *
- @param[in] task_id Identifier of the task. Use @ref RTEMS_SELF to select
- the executing task.
- @param[out] scheduler_id Identifier of the scheduler. *
- @retval RTEMS_SUCCESSFUL Successful operation.
- @retval RTEMS_INVALID_ID Invalid task identifier. */
rtems_status_code rtems_task_get_scheduler(
rtems_id task_id, rtems_id *scheduler_id
);
Scheduler Configuration
There are two options for the scheduler instance configuration
# static configuration by means of global data structures, and # configuration at run-time via function calls.
For a configuration at run-time the system must start with a default scheduler. The global constructors are called in this environment. The order of global constructor invocation is unpredictable so it is difficult to create threads in this context since the run-time scheduler configuration may not exist yet. Since scheduler data structures are allocated from the workspace the configuration must take a later run-time setup of schedulers into account for the workspace size estimate. In case the default scheduler is not appropriate it must be replaced which gives raise to some implementation difficulties. Since the processor availability is determined by hardware constraints it is unclear which benefits a run-time configuration has. For now run-time configuration of scheduler instances will be not implemented.
The focus is now on static configuration. Every scheduler needs a control context. The scheduler API must provide a macro which creates a global scheduler instance specific data structure with a designator name as a mandatory parameter. The scheduler instance creation macro may require additional scheduler specific configuration options. For example a fixed-priority scheduler instance must know the maximum priority level to allocate the ready chain control table.
Once the scheduler instances are configured it must be specified for each processor in the system which scheduler instance owns this processor or if this processor is not used by the RTEMS system.
For each processor except the initialization processor a scheduler instance is optional so that other operating systems can run independent of this RTEMS system on this processor. It is a fatal error to omit a scheduler instance for the initialization processor. The initialization processor is the processor which executes the boot_card() function.
/
- @brief Processor configuration. *
- Use RTEMS_CPU_CONFIG_INIT() to initialize this structure. */
typedef struct {
/
- @brief Scheduler instance for this processor. *
- It is possible to omit a scheduler instance for this processor by using
- the @c NULL pointer. In this case RTEMS will not use this processor and
- other operating systems may claim it. */
Scheduler_Control *scheduler;
} rtems_cpu_config;
/
- @brief Processor configuration initializer. *
- @param scheduler The reference to a scheduler instance or @c NULL. *
- @see rtems_cpu_config. */
#define RTEMS_CPU_CONFIG_INIT(scheduler) \
{ ( scheduler ) }
Scheduler and processor configuration example:
RTEMS_SCHED_DEFINE_FP_SMP(fp0, rtems_build_name(' ', 'F', 'P', '0'), 256); RTEMS_SCHED_DEFINE_FP_SMP(fp1, rtems_build_name(' ', 'F', 'P', '1'), 64); RTEMS_SCHED_DEFINE_EDF_SMP(edf0, rtems_build_name('E', 'D', 'F', '0'));
const rtems_cpu_config rtems_cpu_config_table[] = {
RTEMS_CPU_CONFIG_INIT(RTEMS_SCHED_REF_FP_SMP(fp0)), RTEMS_CPU_CONFIG_INIT(RTEMS_SCHED_REF_FP_SMP(fp1)), RTEMS_CPU_CONFIG_INIT(RTEMS_SCHED_REF_FP_SMP(fp1)), RTEMS_CPU_CONFIG_INIT(RTEMS_SCHED_REF_FP_SMP(fp1)), RTEMS_CPU_CONFIG_INIT(NULL), RTEMS_CPU_CONFIG_INIT(NULL), RTEMS_CPU_CONFIG_INIT(RTEMS_SCHED_REF_EDF_SMP(edf0)), RTEMS_CPU_CONFIG_INIT(RTEMS_SCHED_REF_EDF_SMP(edf0)
};
const size_t rtems_cpu_config_count =
RTEMS_ARRAY_SIZE(rtems_cpu_config_table);
An alternative to the processor configuration table would be to specify in the scheduler instance which processors are owned by the instance. This would require a static initialization of CPU sets which is difficult. Also the schedulers have to be registered somewhere, so some sort of table is needed anyway. Since a processor can be owned by at most one scheduler instance this configuration approach enables an additional error source which is avoided by the processor configuration table.
Scheduler Implementation
Currently the scheduler operations have no control context and use global variables instead. Thus the scheduler operations signatures must change to use a scheduler control context as the first parameter, e.g.
typedef struct Scheduler_Control Scheduler_Control;
typedef struct {
[...] void ( *set_affinity )(
Scheduler_Control *self, Thread_Control *thread, size_t affinity_set_size, const cpu_set_t *affinity_set
); [...]
} Scheduler_Operations;
/
- @brief General scheduler control. */
struct Scheduler_Control {
/
- @brief The scheduler operations. */
Scheduler_Operations Operations;
/
- @brief Size of the owned processor set in bytes. */
size_t owned_cpu_set_size
/
- @brief Reference to the owned processor set. *
- A set bit means this processor is owned by this scheduler instance, a
- cleared bit means the opposite. */
cpu_set_t *owned_cpu_set;
};
Single processor configurations benefit also from this change since it makes all dependencies explicit and easier to access (allows more efficient machine code).
Multiprocessor Resource Sharing Protocol - MrsP
Reason
In general, application-level threads are not independent and may indeed share logical resources. In a partitioned-scheduling system, where capacity allows, resources are allocated on the same processor as the threads that share it: in that case those resources are termed local. Where needed, resources may also reside on processors other than that of (some of) their sharing threads: in that case those resources are termed global.
For partitioned scheduling of application-level threads and local resources, two choices are possible, which meet the ITT requirement of achieving predictable time behaviour for platform software
- (1) fixed-priority scheduling with the immediate priority ceiling for controlling access to local resources, or
- (2) EDF scheduling with the stack resource protocol for controlling access to local resources.
Choice (1) is more natural with RTEMS. Both alternatives require preemption, whose disruption to the thread's cache working set may in part be attenuated by the use of techniques known as limited-preemption, which have been successfully demonstrated by the UoP. Conversely, run-to-completion (non-preemptive) semantics is known to achieve much lower schedulable utilization, which cannot make it a plausible candidate for performance-hungry systems. The use of fixed-priority scheduling for each processor where application-level threads locally run allows response time analysis to be used, which, on the basis of the worst-case execution time of individual threads and on the graph of resource usage among threads, determines the worst-case completion time of every individual thread run on that processor, offering absolute guarantees on the schedulable utilization of every individual processor that uses that algorithm.
The determination of worst-case execution time of software programs running on one processor of an SMP is significantly more complex than its single-processor analogous. This is because every local execution suffers massive interference effects from its co-runners on other processors, regardless of functional independence. Simplistically upper bounding the possible interference incurs exceeding pessimism, which causes massive reduction in the allowable system load. More accurate interference analysis may incur prohibitive costs unless simplifying assumptions can be safely made, one of which is strictly static partitioning: previous studies run by ESA http://microelectronics.esa.int/ngmp/MulticoreOSBenchmark-FinalReport_v7.pdf have indicated possible approaches to that problem. Global scheduling greatly exacerbates the difficulty of that problem and thus is unwelcome. With fixed-priority scheduling, each logical resource shared by multiple application-level threads (or their corresponding lock) must be statically attached a ceiling priority attribute computed as an upper bound to the static priority of all threads that may use that resource: when an application-level thread acquires the resource lock, the priority of that thread is raised to the ceiling of the resource; upon relinquishing the lock to that resource, the thread must return to the priority level that it had prior to acquiring the lock. (It has been shown that the implementation of this protocol does not need resource locks at all, as the mere fact for a thread to be running implies that all of the resources that it may want to use are free at this time and none can be claimed by lower-priority threads. However, it may be easier for an operating system to attach the ceiling value to the resource lock than to any other data structures.) This simple protocol allows application-level threads to acquire multiple resources without risking deadlock.
When global resources are used, which is very desirable to alleviate the complexity of task allocation, the resource access control protocol in use, whether (1) or (2) in the earlier taxonomy, must be specialized, so that global resources can be syntactically told apart from local resources. Luckily, two solutions have been very recently proposed to address this problem. One solution, known as Optimal Migratory Priority Inheritance (OMIP), was proposed by Björn Brandenburg in his work entitled A Fully Preemptive Multiprocessor Semaphore Protocol for Latency-Sensitive Real-Time Applications, presented at the ECRTS conference in July 2013. The other solution, known as Multiprocessor Resource Sharing Protocol (MrsP), was proposed by Alan Burns and Andy Wellings in their work entitled A Schedulability Compatible Multiprocessor Resource Sharing Protocol, presented at the very same ECRTS 2013 conference. OMIP aims to solve the problem of guaranteed bounded blocking in global resource sharing in clustered scheduling on a multiprocessor, where a cluster is a collection of at least one processor. MrsP aims to achieve the smallest bound to the cumulative duration of blocking suffered by threads waiting to access a global resource in partitioned scheduling (clusters with exactly one processor), while allowing schedulability analysis to be performed per processor, using response time analysis, which is a technique fairly well known to industry. No other global resource sharing protocol on SMP, including OMIP, is able to guarantee that. For this reason MrsP is the choice for this study.
The MrsP protocol requires that
- (a) threads waiting for global resources spin at ceiling priority on their local processor, and with a ceiling value greater than any other local resource on that processor, and
- (b) the execution within the global resource may migrate to other processors where application-level threads waiting to access that resource are spinning.
Feature (a) prevents lower-priority threads from running in preference to the waiting higher-priority thread and stealing resources that it might want to use in the future as part of the current execution; should that stealing happen, the blocking penalty potentially suffered on access to global resources would skyrocket to untenable levels. Feature (b), which brings in the sole welcome extent of migration in the proposed model, which is useful when higher-priority tasks running on the processor of the global resource prevent it from completing execution; in that case, the slack allowed for by local spinning on other processors where other threads are waiting, is used to speed up the completion of the execution in the global resource and therefore reduce blocking.
Status
Implementation is complete http://git.rtems.org/rtems/commit/?id=5c3d2509593476869e791111cd3d93cc1e840b3a.
RTEMS API Changes
A new semaphore attribute enables MrsP.
/
- @brief Semaphore attribute to select the multiprocessor resource sharing
- protocol MrsP. *
- This attribute is mutually exclusive with RTEMS_PRIORITY_CEILING and
- RTEMS_INHERIT_PRIORITY. */
#define RTEMS_MULTIPROCESSOR_RESOURCE_SHARING 0x00000100
For MrsP we need the ability to specify the priority ceilings per scheduler domain.
typedef struct {
rtems_id scheduler_id; rtems_task_priority priority;
} rtems_task_priority_by_scheduler;
/
- @brief Sets the priority ceilings per scheduler for a semaphore with
- priority ceiling protocol. *
- @param[in] semaphore_id Identifier of the semaphore.
- @param[in] priority_ceilings A table with priority ceilings by scheduler.
- In case one scheduler appears multiple times, the setting with the highest
- index will be used. This semaphore object is then bound to the specified
- scheduler domains. It is an error to use this semaphore object on other
- scheduler domains. The specified schedulers must be compatible, e.g.
- migration from one scheduler domain to another must be defined.
- @param[in] priority_ceilings_count Count of priority ceilings by scheduler
- pairs in the table. *
- @retval RTEMS_SUCCESSFUL Successful operation.
- @retval RTEMS_INVALID_ID Invalid semaphore identifier.
- @retval RTEMS_INVALID_SECOND_ID Invalid scheduler identifier in the table.
- @retval RTEMS_INVALID_PRIORITY Invalid task priority in the table. */
rtems_status_code rtems_semaphore_set_priority_ceilings(
rtems_id semaphore_id, const rtems_task_priority_by_scheduler *priority_ceilings, size_t priority_ceilings_count
);
Implementation
The critical part in the MrsP is the migration of the lock holder in case of preemption by a higher-priority thread. A post-switch action is used to detect this event. The post-switch action will remove the thread from the current scheduler domain and add it to the scheduler domain of the first waiting thread which is executing. A resource release will remove this thread from the temporary scheduler domain and move it back to the original scheduler domain.
Fine Grained Locking
Reason
Fine grained locking is of utmost importance to get a scalable operating system that can guarantee reasonable worst-case latencies. With the current Giant lock in RTEMS the worst-case latencies of every operating system service increase with each processor added to the system. Since the Giant lock state is shared among all processors a huge cache synchronization overhead contributes to the worst-case latencies. Fine grained locking in combination with partitioned/clustered scheduling helps to avoid these problems since now the operating system state is distributed allowing true parallelism of independent components.
Status
This is TBD.
RTEMS API Changes
None.
Locking Protocol Analysis
As a sample operating system operation the existing mutex obtain/release/timeout sequences will be analysed. All ISR disable/enable points (highlighted with colours) must be turned into an appropriate SMP clock (e.g. a ticket spin lock). One goal is that an uncontested mutex obtain will use no SMP locks except the one associated with the mutex object itself. Is this possible with the current structure?
mutex_obtain(id, wait, timeout):
<span style="color:red">level = ISR_disable()</span> mtx = mutex_get(id) executing = get_executing_thread() wait_control = executing.get_wait_control() wait_control.set_status(SUCCESS) if !mtx.is_locked():
mtx.lock(executing) if mtx.use_ceiling_protocol():
thread_dispatch_disable() <span style="color:red">ISR_enable(level)</span> executing.boost_priority(mtx.get_ceiling()) thread_dispatch_enable()
else:
<span style="color:red">ISR_enable(level)</span>
else if mtx.is_holder(executing):
mtx.increment_nest_level() <span style="color:red">ISR_enable(level)</span>
else if !wait:
<span style="color:red">ISR_enable(level)</span> wait_control.set_status(UNSATISFIED)
else:
wait_queue = mtx.get_wait_queue() wait_queue.set_sync_status(NOTHING_HAPPENED) executing.set_wait_queue(wait_queue)) thread_dispatch_disable() <span style="color:red">ISR_enable(level)</span> if mtx.use_inherit_priority():
mtx.get_holder().boost_priority(executing.get_priority()))
<span style="color:fuchsia">level = ISR_disable()</span> if executing.is_ready():
executing.set_state(MUTEX_BLOCKING_STATE) scheduler_block(executing)
else:
executing.add_state(MUTEX_BLOCKING_STATE)
<span style="color:fuchsia">ISR_enable(level)</span> if timeout:
timer_start(timeout, executing, mtx)
<span style="color:blue">level = ISR_disable()</span> search_thread = wait_queue.first() while search_thread != wait_queue.tail():
if executing.priority() <= search_thread.priority():
break
<span style="color:blue">ISR_enable(level)</span> <span style="color:blue">level = ISR_disable()</span> if search_thread.is_state_set(MUTEX_BLOCKING_STATE):
search_thread = search_thread.next()
else:
search_thread = wait_queue.first()
sync_status = wait_queue.get_sync_status() if sync_state == NOTHING_HAPPENED:
wait_queue.set_sync_status(SYNCHRONIZED) wait_queue.enqueue(search_thread, executing) executing.set_wait_queue(wait_queue) <span style="color:blue">ISR_enable(level)</span>
else:
executing.set_wait_queue(NULL) if executing.is_timer_active():
executing.deactivate_timer() <span style="color:blue">ISR_enable(level)</span> executing.remove_timer()
else:
<span style="color:blue">ISR_enable(level)</span>
<span style="color:fuchsia">level = ISR_disable()</span> if executing.is_state_set(MUTEX_BLOCKING_STATE):
executing.clear_state(MUTEX_BLOCKING_STATE) if executing.is_ready():
scheduler_unblock(executing)
<span style="color:fuchsia">ISR_enable(level)</span>
thread_dispatch_enable()
return wait_control.get_status()
mutex_release(id):
thread_dispatch_disable() mtx = mutex_get(id) executing = get_executing_thread() nest_level = mtx.decrement_nest_level() if nest_level == 0:
if mtx.use_ceiling_protocol() or mtx.use_inherit_priority():
executing.restore_priority()
wait_queue = mtx.get_wait_queue() thread = NULL <span style="color:red">level = ISR_disable()</span> thread = wait_queue.dequeue() if thread != NULL:
thread.set_wait_queue(NULL) if thread.is_timer_active():
thread.deactivate_timer() <span style="color:red">ISR_enable(level)</span> thread.remove_timer()
else:
<span style="color:red">ISR_enable(level)</span>
<span style="color:fuchsia">level = ISR_disable()</span> if thread.is_state_set(MUTEX_BLOCKING_STATE):
thread.clear_state(MUTEX_BLOCKING_STATE) if thread.is_ready():
scheduler_unblock(thread)
<span style="color:fuchsia">ISR_enable(level)</span>
else:
<span style="color:red">ISR_enable(level)</span>
<span style="color:blue">level = ISR_disable()</span> if thread == NULL:
sync_status = wait_queue.get_sync_status()
if sync_status == TIMEOUT sync_status == NOTHING_HAPPENED: wait_queue.set_sync_status(SATISFIED) thread = executing
<span style="color:blue">ISR_enable(level)</span> if thread != NULL:
mtx.new_holder(thread) if mtx.use_ceiling_protocol():
thread.boost_priority(mtx.get_ceiling())
else:
mtx.unlock()
thread_dispatch_enable()
mutex_timeout(thread, mtx):
<span style="color:red">level = ISR_disable()</span> wait_queue = thread.get_wait_queue() if wait_queue != NULL:
sync_status = wait_queue.get_sync_status() if sync_status != SYNCHRONIZED and thread.is_executing():
if sync_status != SATISFIED:
wait_queue.set_sync_status(TIMEOUT) wait_control = executing.get_wait_control() wait_control.set_status(TIMEOUT)
<span style="color:red">ISR_enable(level)</span>
else:
<span style="color:red">ISR_enable(level)</span> <span style
Attachments (5)
-
rtems-smp-affinity.png (33.8 KB) - added by Amar Takhar on 02/10/15 at 13:46:41.
Add missing image.
-
rtems-smp-events.png (122.3 KB) - added by Amar Takhar on 02/10/15 at 13:46:51.
Add missing image.
-
rtems-smp-isr-1.png (34.7 KB) - added by Amar Takhar on 02/10/15 at 13:47:10.
Add missing image.
-
rtems-smp-isr-2.png (48.5 KB) - added by Amar Takhar on 02/10/15 at 13:47:19.
Add missing image.
-
rtems-smp-low-level-states.png (34.0 KB) - added by Amar Takhar on 02/10/15 at 13:47:28.
Add missing image.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip