| Version 29 (modified by Sh, on 01/13/14 at 16:05:09) (diff) |
|---|
SMP
Table of Contents
- SMP
- Status
- Requirements
- Design Issues
- Low-Level Start
- Processor Affinity
- Atomic Operations
- SMP Locks
- ISR Locks
- Giant Lock vs. Fine Grained Locking
- Watchdog Handler
- Per-CPU Control
- Interrupt Support
- Global Scheduler
- Clustered Scheduling
- Task Variables
- Non-Preempt Mode for Mutual Exclusion
- Thread Restart
- = Thread Delete =
- === Status ===
Status
The SMP support for RTEMS is work in progress. Basic support is available for ARM, PowerPC, SPARC and Intel x86.
Requirements
No public requirements exist currently.
Design Issues
Low-Level Start
Status
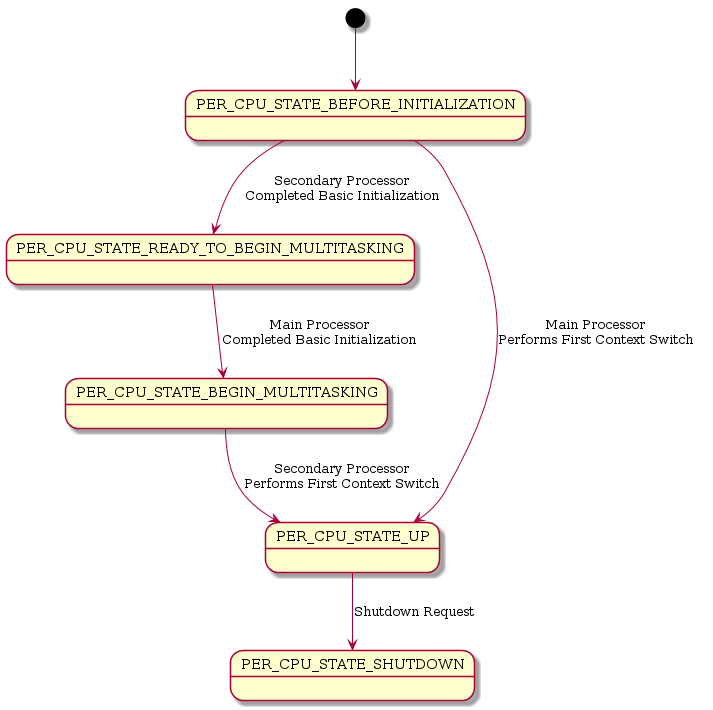
The low-level start is guided by the per-CPU control state Per_CPU_Control::state. See also _Per_CPU_Change_state() and _Per_CPU_Wait_for_state().
File:rtems-smp-low-level-states.png?
Future Directions
Get rid of _CPU_Context_switch_to_first_task_smp() and use _CPU_Context_restore() instead since this complicates things. This function is only specific on SPARC other architectures like ARM or PowerPC do not need it. The low-level initialization code of secondary processors can easily set up the processor into the right state.
Processor Affinity
Status
Thread processor affinity is not supported.
Future Directions
Implement the missing feature. This consists of two parts
- the application level API, and
- the scheduler support.
There is no POSIX API available that covers thread processor affinity. Linux is the de facto standard system for high performance computing so it is obvious to choose a Linux compatible API for RTEMS. Linux provides CPU_SET(3) to manage sets of processors. Thread processor affinity can be controlled via SCHED_SETAFFINITY(2) and PTHREAD_SETAFFINITY_NP(3). RTEMS should provide these APIs and implement them. It is not possible to use the Linux files directly since they have a pure GPL license.
The scheduler support for arbitrary processor affinities is a major challenge. Schedulability analysis for schedulers with arbitrary processor affinities is a current research topic <ref name="Gujarati2013>Arpan Gujarati, Felipe Cerqueira, and Björn Brandenburg. Schedulability Analysis of the Linux Push and Pull Scheduler with Arbitrary Processor Affinities, Proceedings of the 25th Euromicro Conference on Real-Time Systems (ECRTS 2013), July 2013.</ref>.
Support for arbitrary processor affinities may lead to massive thread migrations in case a new thread is scheduled. Suppose we have M processors 0, ..., M - 1 and M + 1 threads 0, ..., M. Thread i can run on processors i and i + 1 for i = 0, ..., M - 2. The thread M - 1 runs only on processor M - 1. The M runs only on processor 0. A thread i has a higher priority than thread i + 1 for i = 0, ..., M, e.g. thread 0 is the highest priority thread. Suppose at time T0 threads 0, ..., M - 2 and M are currently scheduled. The thread i runs on processor i + 1 for i = 0, ..., M - 2 and thread M runs on processor 0. Now at time T1 thread M - 1 gets ready. It casts out thread M since this is the lowest priority thread. Since thread M - 1 can run only on processor M - 1, the threads 0, ..., M - 2 have to migrate from processor i to processor i - 1 for i = 0, ..., M - 2. So one thread gets ready and the threads of all but one processor must migrate. The threads forced to migrate all have a higher priority than the new ready thread M - 1. {| class="wikitable" |+ align="bottom" | Example for M = 3 ! Time ! Thread ! Processor 0 ! Processor 1 ! Processor 2
| rowspan="4" | T0 | 0 | | style="background-color:green" | |
| 1 | | | style="background-color:yellow" |
| 2 | | |
| 3 | style="background-color:red" | | |
| rowspan="4" | T1 | 0 | style="background-color:green" | | |
| 1 | | style="background-color:yellow" | |
| 2 | | | style="background-color:purple" |
| 3 | | |
|}
In the example above the Linux Push and Pull scheduler would not find a processor for thread M - 1 = 2 and thread M = 3 would continue to execute even though it has a lower priority.
The general scheduling problem with arbitrary processor affinities is a matching problem in a bipartite graph. There are two disjoint vertex sets. The set of ready threads and the set of processors. The edges indicate that a thread can run on a processor. The scheduler must find a maximum matching which fulfills in addition other constraints. For example the highest priority threads should be scheduled first. The performed thread migrations should be minimal. The augmenting path algorithm needs O(VE) time to find a maximum matching, here V is the ready thread count plus processor count and E is the number of edges. It is particularly bad that the time complexity depends on the ready thread count. It is an open problem if an algorithm exits that is good enough for real-time applications.
Atomic Operations
Status
The <stdatomic.h> header file is now available in Newlib. GCC 4.8 supports C11 atomic operations. Proper atomic operations support for LEON3 is included in GCC 4.9. According to the SPARC GCC maintainer it is possible to back port this to GCC 4.8. A GSoC 2013 project works on an atomic operations API for RTEMS. One part will be a read-write lock using a phase-fair lock implementation.
Example ticket lock with C11 atomics.
#include <stdatomic.h>
struct ticket {
atomic_uint ticket; atomic_uint now_serving;
};
void acquire(struct ticket *t) {
unsigned int my_ticket = atomic_fetch_add_explicit(&t->ticket, 1, memory_order_relaxed);
while (atomic_load_explicit(&t->now_serving, memory_order_acquire) != my_ticket) {
/* Wait */
}
}
void release(struct ticket *t) {
unsigned int current_ticket = atomic_load_explicit(&t->now_serving, memory_order_relaxed);
atomic_store_explicit(&t->now_serving, current_ticket + 1U, memory_order_release);
}
The generated assembler code looks pretty good. Please note that GCC generates CAS instructions and not CASA instructions.
.file "ticket.c" .section ".text" .align 4 .global acquire .type acquire, #function .proc 020
acquire:
ld [%o0], %g1 mov %g1, %g2
.LL7:
add %g1, 1, %g1 cas [%o0], %g2, %g1 cmp %g1, %g2 bne,a .LL7
mov %g1, %g2
add %o0, 4, %o0
.LL4:
ld [%o0], %g1 cmp %g1, %g2 bne .LL4
nop
jmp %o7+8
nop
.size acquire, .-acquire .align 4 .global release .type release, #function .proc 020
release:
ld [%o0+4], %g1 add %g1, 1, %g1 st %g1, [%o0+4] jmp %o7+8
nop
.size release, .-release .ident "GCC: (GNU) 4.9.0 20130917 (experimental)"
Future Directions
- Review and integrate the GSoC work.
- Make use of atomic operations.
SMP Locks
Status
The implementation is now CPU architecture specific.
Future Directions
- Use a fair lock on SPARC and x86, e.g. a ticket lock like on ARM and PowerPC.
- Use a local context to be able to use scalable lock implementations like the Mellor-Crummey and Scotty (MCS) queue-based locks.
- Introduce read-write locks. Use phase-fair read-write lock implementation. This can be used for example by the time management code. The system time may be read frequently, but updates are infrequent.
ISR Locks
Status
On single processor configurations disabling of interrupts ensures mutual exclusion. This is no longer true on SMP since other processors continue to execute freely. On SMP the disabling of interrupts must be combined with an SMP lock. The ISR locks degrade to simple interrupt disable/enable sequences on single processor configurations. On SMP configurations they use an SMP lock to ensure mutual exclusion throughout the system.
Future Directions
- See SMP locks.
- Ensure via a RTEMS assertion that normal interrupt disable/sequences are only used intentional outside of the Giant lock critical sections. Review usage of ISR disable/enable sequences of the complete code base.
Giant Lock vs. Fine Grained Locking
Status
The operating system state is currently protected by three things
- the per-processor thread dispatch disable level,
- the Giant lock (a global recursive SMP lock), and
- the disabling of interrupts.
For example the operating services like rtems_semaphore_release() follow this pattern:
operation(id):
disable_thread_dispatching() acquire_giant_lock() obj = get_obj_by_id(id) status = obj->operation() put_object(obj) release_giant_lock() enable_thread_dispatching() return status
All high level operations are serialized due to the Giant lock. The introduction of the Giant lock allowed a straight forward usage of the existing single processor code in an SMP configuration. However a Giant lock will likely lead to undesirable high worst case latencies which linear increase with the processor count <ref name="Brandenburg2011">Björn B. Brandenburg, Scheduling and Locking in Multiprocessor Real-Time Operating Systems, 2011.</ref>.
Future Directions
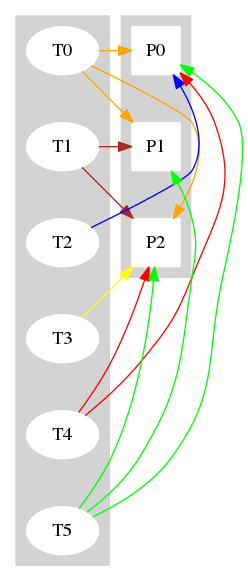
The Giant lock should be replaced with fine grained locking. In order to introduce fine grained locking the state transitions inside a section protected by the Giant lock must be examined. As an example the event send and receive operations are presented in a simplified state diagram.
The colour indicates which locks are held during a state and state transition. In case of a blocking operation we have four synchronization states which are used to split up the complex blocking operation into parts in order to decrease the interrupt latency
- nothing happened,
- satisfied,
- timeout, and
- synchronized.
This state must be available for each thread and resource (e.g. event, semaphore, message queue). Since this would lead to a prohibitive high memory demand and a complicated implementation some optimizations have been performed in RTEMS. For events a global variable is used to indicate the synchronization state. For resource objects the synchronization state is part of the object. Since at most one processor can execute a blocking operation (ensured by the Giant lock or the singe processor configuration) it is possible to use the state variable only for the executing thread.
In case one SMP lock is used per resource the resource must indicate which thread is about to perform a blocking operation since more than one executing thread exists. For example two threads can try to obtain different semaphores on different processors at the same time.
A blocking operation will use not only the resource object, but also other resources like the scheduler shared by all threads of a dispatching domain. Thus the scheduler needs its own locks. This will lead to nested locking and deadlocks must be prevented.
Watchdog Handler
Status
The Watchdog Handler is a global resource which provides time management in RTEMS. It is a core service of the operating system and used by the high level APIs. It is used for time of day maintenance and time events based on ticks or wall clock time for example. The term watchdog has nothing to do with hardware watchdogs.
Future Directions
The watchdog uses delta chains to manage time based events. One global watchdog resource leads to scalability problems. A SMP system is scalable if additional processors will increase the performance metrics. If we add more processors, then in general the number of timers increases proportionally and thus leads to longer delta chains. Also the chance for lock contention increases. Thus the watchdog resource should move to the scheduler scope with per scheduler instances. Additional processors can then use new scheduler instances.
Per-CPU Control
Status
Per-CPU control state is available for each configured CPU in a statically created global table _Per_CPU_Information. Each per-CPU control is cache aligned to prevent false sharing and to provide simple access via assembly code. CPU ports can add custom fields to the per-CPU control. This is used on SPARC for the ISR dispatch disable indication.
Future Directions
None.
Interrupt Support
Status
The interrupt support is BSP specific in general.
Future Directions
- The SMP capable BSPs should implement the Interrupt Manager Extension.
- Add interrupt processor affinity API to Interrupt Manager Extension. This should use the affinity sets API used for thread processor affinity.
Global Scheduler
Status
- Scheduler selection is a link-time configuration option.
- Basic SMP support for schedulers like processor allocation and extended thread state information.
- Two global fixed priority schedulers (G-FP) are available with SMP support.
Future Directions
- Add more schedulers, e.g. EDF, phase-fair, early-release fair, etc.
- Allow thread processor affinity selection for each thread.
- The scheduler operations have no context parameter instead they use the global variable '_Scheduler'. The scheduler operations signature should be changed to use a parameter for the scheduler specific context to allow more than one scheduler in the system. This can be used to enable scheduler hierarchies or partitioned schedulers.
- The scheduler locking is inconsistent. Some scheduler operations are invoked with interrupts disabled. Some like the yield operations are called without interrupts disabled and must disable interrupts locally.
- The new SMP schedulers lack test coverage.
- Implement clustered (or partitioned) scheduling with a sophisticated resource sharing protocol (e.g. <ref name="BurnsWellings2013">A. Burns and A.J. Wellings, A Schedulability Compatible Multiprocessor Resource Sharing Protocol - MrsP, Proceedings of the 25th Euromicro Conference on Real-Time Systems (ECRTS 2013), July 2013. </ref>). To benefit from this the Giant lock must be eliminated.
Clustered Scheduling
Status
Clustered scheduling is not supported.
Future Directions
Suppose we have a set of processors. The set of processors can be partitioned into non-empty, pairwise disjoint subsets. Such a subset is called a dispatching domain. Dispatching domains should be set up in the initialization phase of the system before application-level threads (and worker threads) can be attached to them. For now the partition must be specified by the application at linktime: this restriction is acceptable in this study project as no change should be allowable to dispatching domains at run time. Associated with each dispatching domain is exactly one scheduler instance. This association (which defines the scheduler algorithm for the domain) must be specified by the application at linktime, upon or after the creation of the dispatching domain. So we have clustered scheduling.
At any one time a thread belongs to exactly one dispatching domain. There will be no scheduling hierarchies and no intersections between dispatching domains. If no dispatching domain is explicitly specified, then it will inherit the one from the executing context to support external code that is not aware of clustered scheduling. This inheritance feature is erroneous and static checks should be made on the program code and link directives to prevent it from happening in this study project.
Do we need the ability to move a thread from one dispatching domain to another? Application-level threads do not migrate. Worker threads do no either. Worker threads do no either. The only allowable (and desirable) migration is for the execution of application-level threads in global resources - not the full task, only that protected execution - in accord with <ref name="BurnsWellings2013"/>.
Task Variables
Status
Task variables cannot be used on SMP. The alternatives are thread-local storage, POSIX keys or special access functions using the thread control block of the executing thread. For Newlib the access to the re-entrancy structure is now performed via getreent(), see also DYNAMIC_REENT in Newlib.
Future Directions
- Fix ADA self task reference.
- Fix file system environment.
- Fix C++ support.
Non-Preempt Mode for Mutual Exclusion
Status
Disabling of thread preemption cannot be used to ensure mutual exclusion on SMP. The non-preempt mode is disabled on SMP and a run-time error will occur if such a mode change request is issued. The alternatives are mutexes and condition variables.
Future Directions
- Add condition variables to the Classic API.
- Fix pthread_once().
- Fix the block device cache bdbuf.
- Fix C++ support.
Thread Restart
Status
The restart of threads other than self is not implemented.
Future Directions
Implement the missing feature. The difficult path is the restart of executing remote threads. Executing remote threads may perform a context switch at any time. This would overwrite a newly initialized thread context. An option is a post-switch handler that performs a self-restart if necessary.
Post-switch handlers have some disadvantages:
- They add a function call via function pointer overhead to every invocation of _Thread_Dispatch(). Post-switch handlers have to check on every invocation if they have something to do.
- Currently post-switch handlers are only used for signal management. Some work was done to install post-switch handlers only on demand since performance measurements showed that they are indeed a problem.
- Depending on the low-level interrupt support they may execute with interrupts disabled and thus increase the worst-case interrupt latency.
- Dynamic add/remove of post-switch handlers is problematic since in this case some lock strategy must be used which makes _Thread_Dispatch() more complex and has an execution overhead.
- Per-CPU specific post-switch handlers are an option. They can use the per-CPU lock which must be obtained in _Thread_Dispatch() anyway.
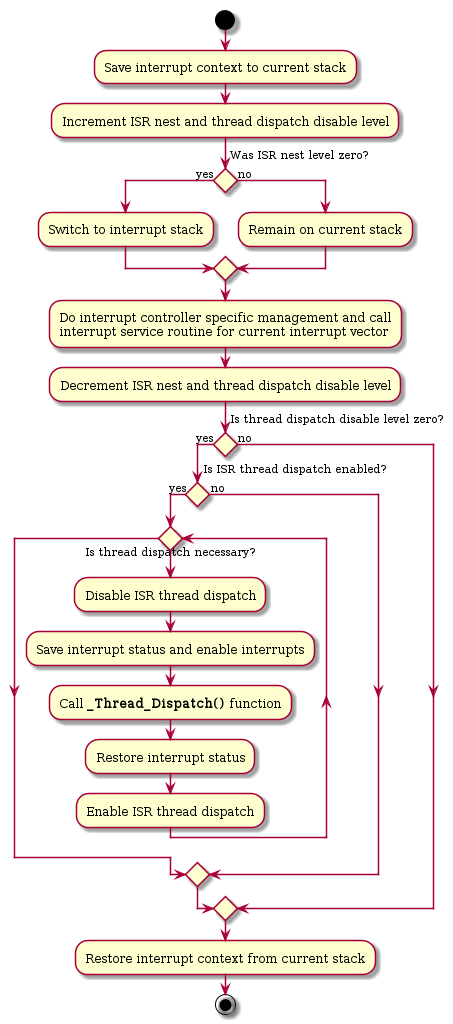
Why execute post-switch handlers with interrupts disabled on some architectures (e.g. ARM and PowerPC)? The most common interrupt handling sequence looks like this:
In this sequence it is not possible to enable interrupts around the _Thread_Dispatch() call. This could lead to an unlimited number of interrupt contexts saved on the thread stack. To overcome this issue some architectures use a flag variable that indicates this particular execution environment (e.g. the SPARC). Here the sequence looks like this:
The ISR thread dispatch disable flag must be part of the thread context. The context switch will save/restore the per-CPU ISR dispatch disable flag to/from the thread context. Each thread stack must have space for at least two interrupt contexts.
This scheme could be used for all architectures. Further discussion is necessary. An alternative to post-switch handlers is currently unknown.
= Thread Delete =
=== Status ===
Deletion of threads is not implemented.
Future Directions
Implement the missing feature. The key problems are lock order reversal issues (Giant vs. allocator lock). Self deletion imposes the problem that some thread resources like the thread stack and the thread object must be freed by a second party. On single processor configurations this was done with a hack that doesn't work on SMP. See also Thread Life-Cycle Changes.
Semaphores and Mutexes
Status
The semaphore and mutex objects use _Objects_Get_isr_disable(). On SMP configurations this first acquires the Giant lock and then interrupts are disabled.
Future Directions
Use an ISR lock per object to improve the performance for uncontested operations. See also Giant Lock vs. Fine Grained Locking.
Implementation
Testing
References
<references/>
Attachments (5)
-
rtems-smp-affinity.png (33.8 KB) - added by Amar Takhar on 02/10/15 at 13:46:41.
Add missing image.
-
rtems-smp-events.png (122.3 KB) - added by Amar Takhar on 02/10/15 at 13:46:51.
Add missing image.
-
rtems-smp-isr-1.png (34.7 KB) - added by Amar Takhar on 02/10/15 at 13:47:10.
Add missing image.
-
rtems-smp-isr-2.png (48.5 KB) - added by Amar Takhar on 02/10/15 at 13:47:19.
Add missing image.
-
rtems-smp-low-level-states.png (34.0 KB) - added by Amar Takhar on 02/10/15 at 13:47:28.
Add missing image.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip