| Version 12 (modified by Sh, on 01/13/14 at 14:18:30) (diff) |
|---|
SMP
Table of Contents
Status
The SMP support for RTEMS is work in progress. Basic support is available for ARM, PowerPC, SPARC and Intel x86.
Requirements
No public requirements exist currently.
Design Issues
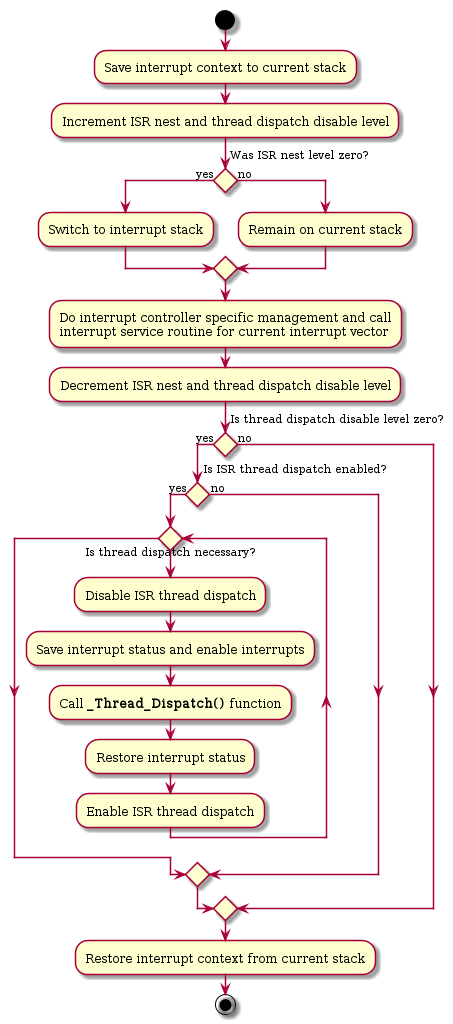
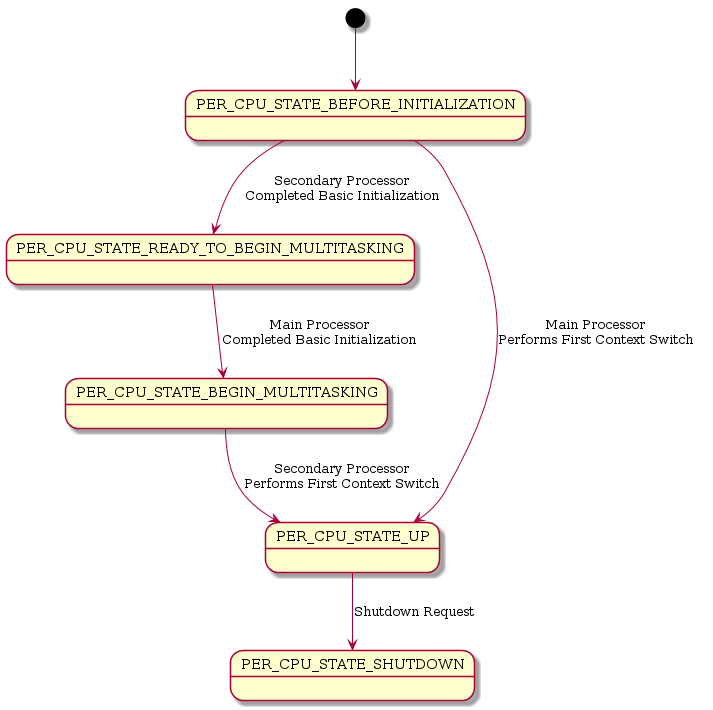
Low-Level Start
Status
The low-level start is guided by the per-CPU control state Per_CPU_Control::state. See also _Per_CPU_Change_state() and _Per_CPU_Wait_for_state().
File:rtems-smp-low-level-states.png?
Future Directions
Get rid of _CPU_Context_switch_to_first_task_smp() and use _CPU_Context_restore() instead since this complicates things. This function is only specific on SPARC other architectures like ARM or PowerPC do not need it. The low-level initialization code of secondary processors can easily set up the processor into the right state.
Processor Affinity
Status
Thread processor affinity is not supported.
Future Directions
Implement the missing feature. This consists of two parts
- the application level API, and
- the scheduler support.
There is no POSIX API available that covers thread processor affinity. Linux is the de facto standard system for high performance computing so it is obvious to choose a Linux compatible API for RTEMS. Linux provides CPU_SET(3) to manage sets of processors. Thread processor affinity can be controlled via SCHED_SETAFFINITY(2) and PTHREAD_SETAFFINITY_NP(3). RTEMS should provide these APIs and implement them. It is not possible to use the Linux files directly since they have a pure GPL license.
The scheduler support for arbitrary processor affinities is a major challenge. Schedulability analysis for schedulers with arbitrary processor affinities is a current research topic <ref name="Gujarati2013>Arpan Gujarati, Felipe Cerqueira, and Björn Brandenburg. Schedulability Analysis of the Linux Push and Pull Scheduler with Arbitrary Processor Affinities, Proceedings of the 25th Euromicro Conference on Real-Time Systems (ECRTS 2013), July 2013.</ref>.
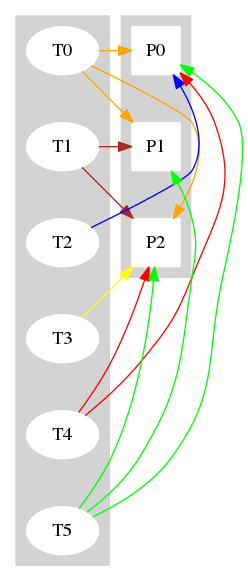
Support for arbitrary processor affinities may lead to massive thread migrations in case a new thread is scheduled. Suppose we have M processors 0, ..., M - 1 and M + 1 threads 0, ..., M. Thread i can run on processors i and i + 1 for i = 0, ..., M - 2. The thread M - 1 runs only on processor M - 1. The M runs only on processor 0. A thread i has a higher priority than thread i + 1 for i = 0, ..., M, e.g. thread 0 is the highest priority thread. Suppose at time T0 threads 0, ..., M - 2 and M are currently scheduled. The thread i runs on processor i + 1 for i = 0, ..., M - 2 and thread M runs on processor 0. Now at time T1 thread M - 1 gets ready. It casts out thread M since this is the lowest priority thread. Since thread M - 1 can run only on processor M - 1, the threads 0, ..., M - 2 have to migrate from processor i to processor i - 1 for i = 0, ..., M - 2. So one thread gets ready and the threads of all but one processor must migrate. The threads forced to migrate all have a higher priority than the new ready thread M - 1. {| class="wikitable" |+ align="bottom" | Example for M = 3 ! Time ! Thread ! Processor 0 ! Processor 1 ! Processor 2
| rowspan="4" | T0 | 0 | | style="background-color:green" | |
| 1 | | | style="background-color:yellow" |
| 2 | | |
| 3 | style="background-color:red" | | |
| rowspan="4" | T1 | 0 | style="background-color:green" | | |
| 1 | | style="background-color:yellow" | |
| 2 | | | style="background-color:purple" |
| 3 | | |
|}
In the example above the Linux Push and Pull scheduler would not find a processor for thread M - 1 = 2 and thread M = 3 would continue to execute even though it has a lower priority.
The general scheduling problem with arbitrary processor affinities is a matching problem in a bipartite graph. There are two disjoint vertex sets. The set of ready threads and the set of processors. The edges indicate that a thread can run on a processor. The scheduler must find a maximum matching which fulfills in addition other constraints. For example the highest priority threads should be scheduled first. The performed thread migrations should be minimal. The augmenting path algorithm needs O(VE) time to find a maximum matching, here V is the ready thread count plus processor count and E is the number of edges. It is particularly bad that the time complexity depends on the ready thread count. It is an open problem if an algorithm exits that is good enough for real-time applications.
Atomic Operations
Status
The <stdatomic.h> header file is now available in Newlib. GCC 4.8 supports C11 atomic operations. Proper atomic operations support for LEON3 is included in GCC 4.9. According to the SPARC GCC maintainer it is possible to back port this to GCC 4.8. A GSoC 2013 project works on an atomic operations API for RTEMS. One part will be a read-write lock using a phase-fair lock implementation.
Example ticket lock with C11 atomics.
#include <stdatomic.h>
struct ticket {
atomic_uint ticket; atomic_uint now_serving;
};
void acquire(struct ticket *t) {
unsigned int my_ticket = atomic_fetch_add_explicit(&t->ticket, 1, memory_order_relaxed);
while (atomic_load_explicit(&t->now_serving, memory_order_acquire) != my_ticket) {
/* Wait */
}
}
void release(struct ticket *t) {
unsigned int current_ticket = atomic_load_explicit(&t->now_serving, memory_order_relaxed);
atomic_store_explicit(&t->now_serving, current_ticket + 1U, memory_order_release);
}
The generated assembler code looks pretty good. Please note that GCC generates CAS instructions and not CASA instructions.
.file "ticket.c" .section ".text" .align 4 .global acquire .type acquire, #function .proc 020
acquire:
ld [%o0], %g1 mov %g1, %g2
.LL7:
add %g1, 1, %g1 cas [%o0], %g2, %g1 cmp %g1, %g2 bne,a .LL7
mov %g1, %g2
add %o0, 4, %o0
.LL4:
ld [%o0], %g1 cmp %g1, %g2 bne .LL4
nop
jmp %o7+8
nop
.size acquire, .-acquire .align 4 .global release .type release, #function .proc 020
release:
ld [%o0+4], %g1 add %g1, 1, %g1 st %g1, [%o0+4] jmp %o7+8
nop
.size release, .-release .ident "GCC: (GNU) 4.9.0 20130917 (experimental)"
Future Directions
- Review and integrate the GSoC work.
- Make use of atomic operations.
SMP Locks
Status
The implementation is now CPU architecture specific.
Future Directions
- Use a fair lock on SPARC and x86, e.g. a ticket lock like on ARM and PowerPC.
- Use a local context to be able to use scalable lock implementations like the Mellor-Crummey and Scotty (MCS) queue-based locks.
- Introduce read-write locks. Use phase-fair read-write lock implementation. This can be used for example by the time management code. The system time may be read frequently, but updates are infrequent.
Implementation
= Testing =
References
<references/>
Attachments (5)
-
rtems-smp-affinity.png (33.8 KB) - added by Amar Takhar on 02/10/15 at 13:46:41.
Add missing image.
-
rtems-smp-events.png (122.3 KB) - added by Amar Takhar on 02/10/15 at 13:46:51.
Add missing image.
-
rtems-smp-isr-1.png (34.7 KB) - added by Amar Takhar on 02/10/15 at 13:47:10.
Add missing image.
-
rtems-smp-isr-2.png (48.5 KB) - added by Amar Takhar on 02/10/15 at 13:47:19.
Add missing image.
-
rtems-smp-low-level-states.png (34.0 KB) - added by Amar Takhar on 02/10/15 at 13:47:28.
Add missing image.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip